Machine Learning 笔记(一) 监督学习、无监督学习
本文主要讲解监督学习、无监督学习相关概念,内容资源来自 Andrew Ng 在 Coursera上的 Machine Learning 课程,在此向 Andrew Ng 致敬。


注:本文内容资源来自 Andrew Ng 在 Coursera上的 Machine Learning 课程,在此向 Andrew Ng 致敬。
一、监督学习(Supervised Learning)
1、Housing Price Prediction 房屋价格预测
对于要买房子的人,充分的市场调研可以充分的了解市场行情。假设你想买一栋 750 feet2 的房子,而在其他方面没有太大的要求,现已收集了许多房屋的尺寸极其对应的价格的信息,如图所示:
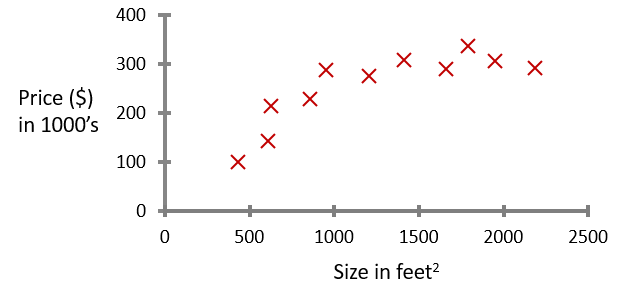
如果你想买一个750 feet2 的房子,大概要多少钱呢?为了让你的估价更加准确,我们最好能求出一个函数,这个函数代表的线最好能代表房价的走势,这样我们就能轻松计算了。如果我们选择了一条直线,如图所示:
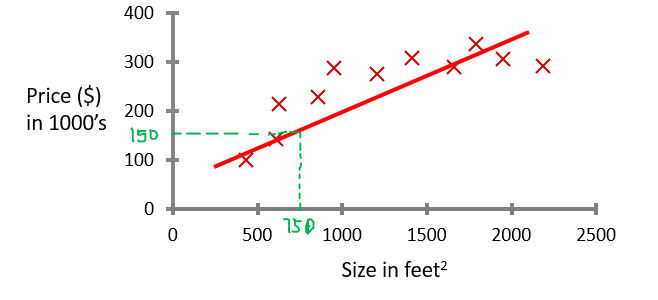
现在我们可以估计,750 feet2 的房子大概值 $150,000 了。但是,从我们的直观感觉来看,房价的走势更像是一条曲线。那么,我们现在选择一条曲线来近似这些数据:
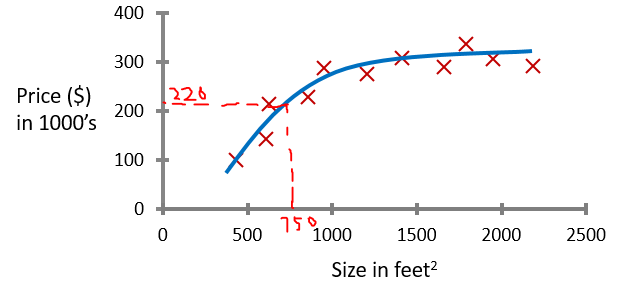
我们发现选择的这条曲线更加地接近数据了。不幸的是,750 feet2 的房子原来要 $220,000。
在这里,就要讲到两个概念:
- 监督学习(Supervised Learning)
对于给定的样例输入,都有特定的输出。
例如房价问题,输入房屋尺寸(Size),输出价值 (Price) 都是已知的。
换句话说,它们都在你的监督范围内。
- 回归(Regression)
找到一条曲线,以预测连续的输出。
例如房价问题,找到一条尺寸-价格曲线,对于任意房屋尺寸都能对其价格进行推测。
回归是解决预测连续输出的一种途径。
与回归相对应的一个概念,就是分类。下面看一个分类问题的例子。
假设要预测一个人的乳腺癌(Breast Canser)是良性(benign)的还是恶性(malignant)的。现在有了肿瘤大小(Tumor Size)和对应是否为恶性(Malignant)的数据,如图所示:
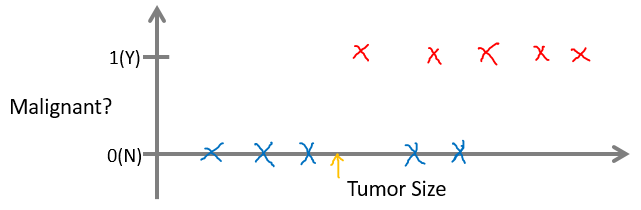
图中,蓝色的 X 代表良性,红色的X代表恶性,那么,橙色的箭头所指,代表的是什么呢?这就是一个两类分类问题。
分类(Classification)
对于输入,它们的输出值可以分为多个离散的类。
例如这个问题中,将输出分为了恶性与良性两类,还可以根据癌症类型分为多个类。
分类的目的就是将数据进行有效的区分。
以上,我们还只讨论了输出仅为一个元素的情况。房价问题上,我们只考虑了房屋的尺寸。癌症问题上,我们只考虑了肿瘤的尺寸。
为确切地进行预测,往往要考虑多方面的因素。例如癌症问题,除了肿瘤尺寸 (Tumor Size),还应考虑患者的年龄(Age)、肿块厚度(Clump Thickness),这样才能更加准确地诊断。我们把年龄这一重要元素加入进来:
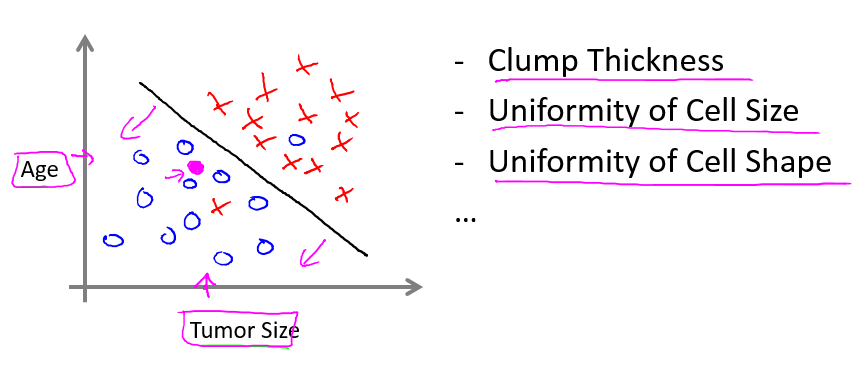
根据肿瘤和患者年龄,进行病情推测,相比只有一个元素时要更加准确。
这里,我们所说的元素,即输入的属性,称为 特征,所有的特征构成的一个向量称作 特征向量。
上图中右侧所罗列的,都是可选的特征,关于特征,将在后面做详细介绍。
二、非监督学习(Unsupervised Learning)
在上面监督学习中,对于给定的输入,都有特定的输出,如下图所示。我们可以明确的看出,哪个样例输出是 O ,哪个样例输出是 X:
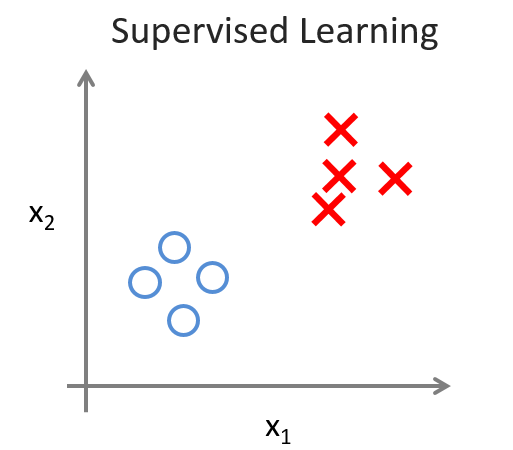
但是,在非监督学习中,情况就不大一样了。对于给定的样例,我们对于它属于哪一类并不明确,如下图所示:
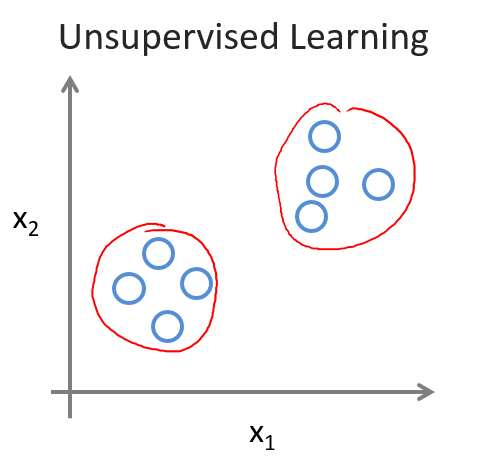
那么,如何进行分类?到底要分成几个类?对于新来的输入,要把它分在哪一个类中?
这一问题要由非监督学习方法来解决。
非监督学习
对于给定的样例,输出并不明确。换句话说,并不在你的掌控之中。
对于一堆混杂的数据,如何利用有效的方法,分出几个类来。
非监督学习的例子有很多,例如 Google News,需要对新闻进行筛选,然后分成 Business、Sci/Tech、Health、Sports 等类别: