Machine Learning 笔记(二) 单变量线性回归
本文主要讲解单变量线性回归相关知识,内容资源来自 Andrew Ng 在 Coursera上的 Machine Learning 课程,在此向 Andrew Ng 致敬。


注:本文内容资源来自 Andrew Ng 在 Coursera上的 Machine Learning 课程,在此向 Andrew Ng 致敬。
一、模型表示(Model Representation)
对于笔记(一)中的房价问题,如何进行求解,这将会是本文中讨论的重点。
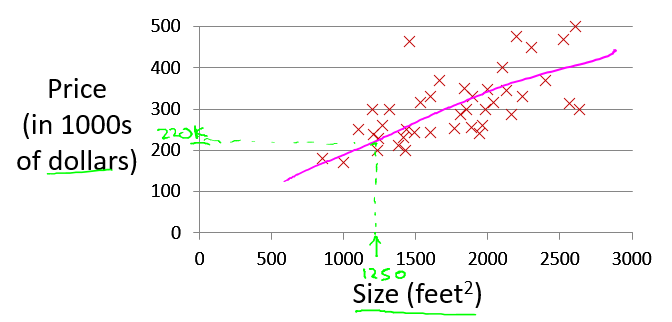
现在假设有了更多的房屋价格数据,需要用一条直线来近似房屋价格的走势,如下图所示:
回顾笔记(一)中所讲 监督学习、非监督学习、回归 和 分类 的概念:
1. 监督学习(Supervised Learning)
对于数据的每一个样例,都有明确的输出值与之对应。
2. 非监督学习(Unsupervised Learning)
对于数据的每一个样例,其输出值名不明确。
3. 回归(Regression)
对于输入样本,预测的输出值是连续的实数。
4. 分类(Classification)
对于输入样本,预测的输出值是离散的。
由此可见,房价问题是一个 监督学习 问题,需要使用 回归 方法求解。
下面给出该问题的一些概念:
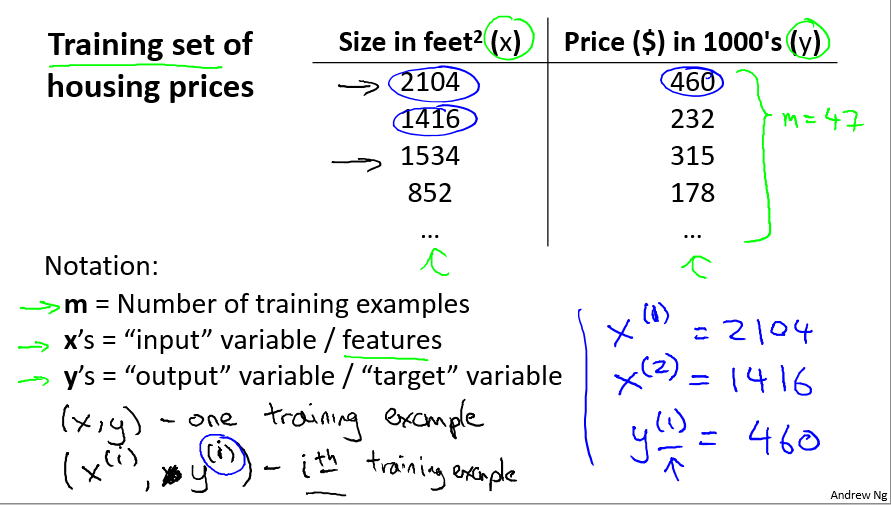
-
m: 训练样本个数
-
x: 输入变量/特征
-
y: 输出变量/目标变量
-
(x(i), y(i)): 第i个训练样本
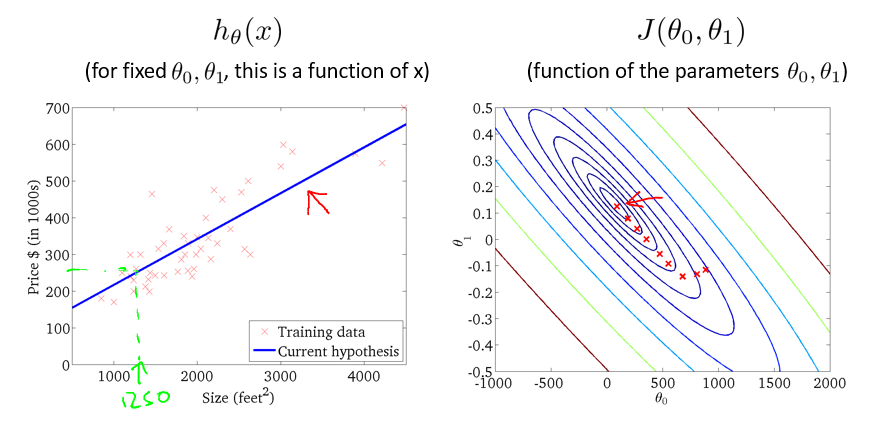
对于给定的训练集(Training Set),我们希望利用学习算法(Learning Algorithm)找到一条直线,以最大地近似所有的数据,然后通过这条直线所表示的函数(h),来推测新的输入(x)的输出值(y),该模型表示如下:
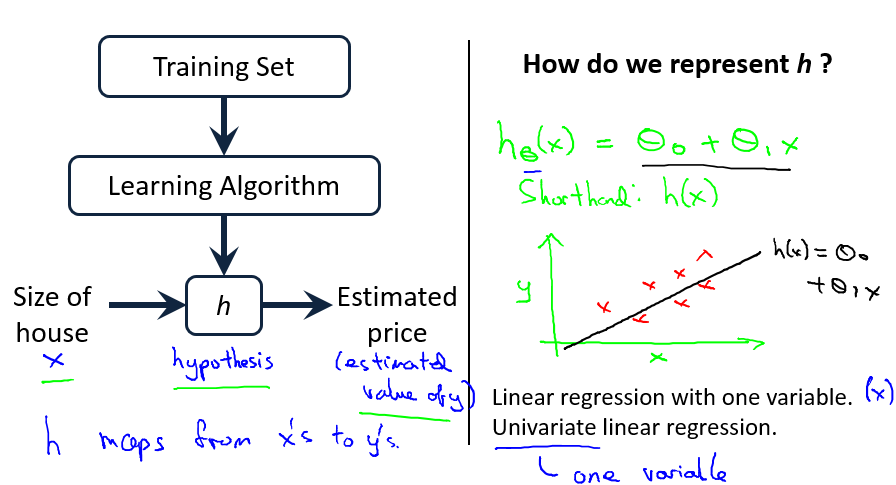
h 往往被称为假设函数,对应着 x 到 y 的映射,由于在本文例子中为一条直线,用上图右侧绿色公式表示。
由于假设函数为线性函数,且训练样本中输入变量只有一个特征(即尺寸),将此类问题称之为 **单变量线性回归(Linear Regression with One Variable,或 Univariate Linear Regression)**问题。
二、代价函数(Cost Function)
继续讨论上述问题的假设函数 h:
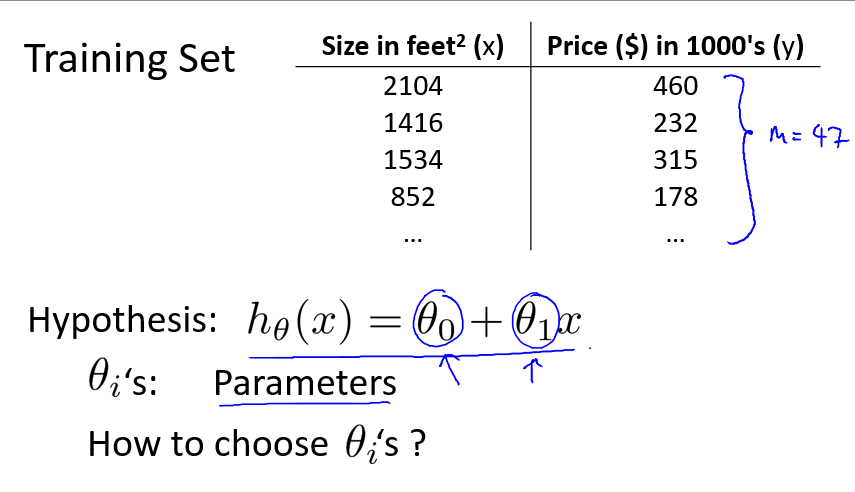
如上图所示,hθ(x) 表示一条关于 x 的直线,θ0 和 θ1 是它的两个参数,要求 hθ(x),就必须确定这两个参数。
那么,如何选择这两个参数呢?
对于只有数据的我们,并不知道 hθ(x) 的参数值,最简单的办法就是假设两个 θ 。对于不同的假设,hθ(x) 表示如下:
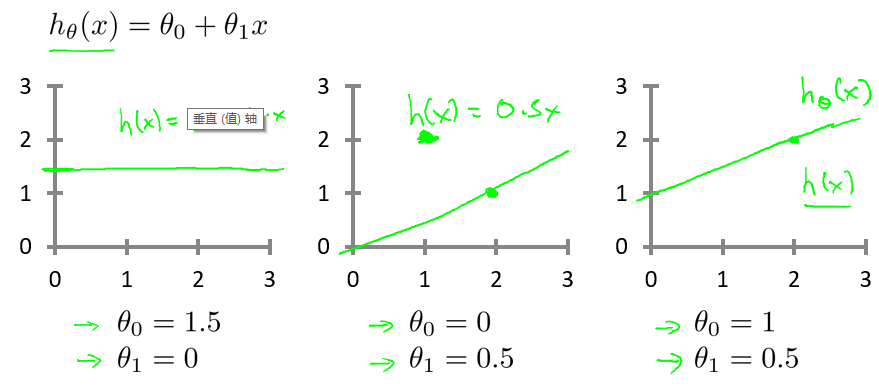
那么,怎么样选择参数 θ ,才能让 hθ(x) 与数据最近似?
一个很好的想法:选择 θ0 和 θ1 ,以使得对于所有的训练样本 (x, y) , hθ(x) 都与 y 最相近。

如何才能说明最相近?我们可以通过调节参数 θ,以最小化所有训练样本点 (x, y) 与预测样本点**(x,hθ(x))** 的距离的平方和来求得。
具体叙述如下:

注:m 表示训练样本个数。将距离的平方和除以 2m,是为了后期求导方便二考虑,对最后结果不会造成影响。
因此,训练的目标,即是调节参数 θ0 和 θ1 ,以最小化代价函数 J(θ0, θ1)。
三、代价函数 直观展现 I(Intuition I)
为了方便的说明求解过程,先做一定的简化,假设 θ0 = 0,如下图右方所示,那么代价函数 J 只与 θ1 相关。

当 θ1 = 1 时,求解过程如下,可得 J(1) = 0 。
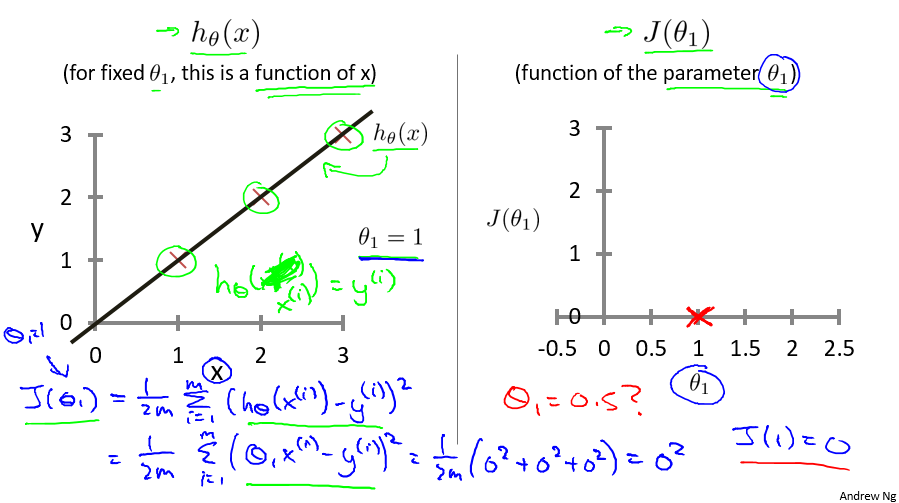
当 θ1 = 0.5 时,求解过程如下,可得 J(0.5) ≈ 0.58 。
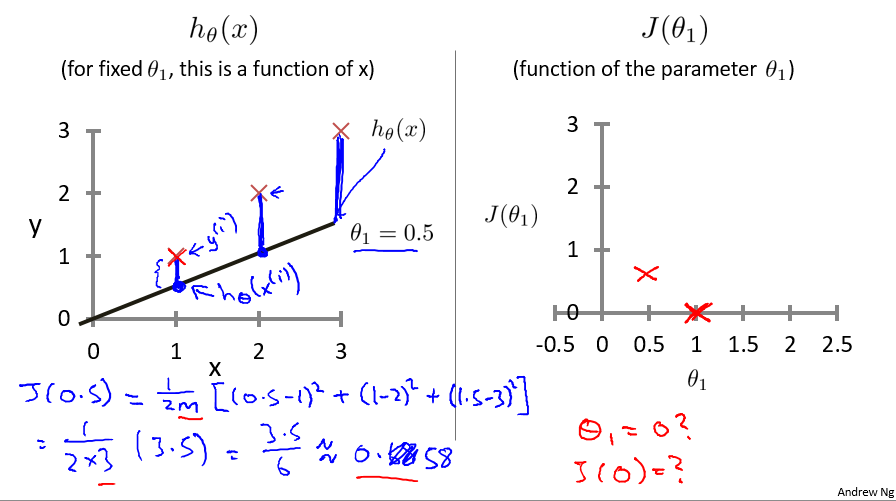
通过不断的尝试 θ1 的值,可以求出相应的 J(θ1) 的值,可以发现,J(θ1) 是关于 θ1 的二次函数,并且对于此样例中的三个数据,在 θ1 = 1 时,J(θ1) 取得最小值,且仅有一个最小值。
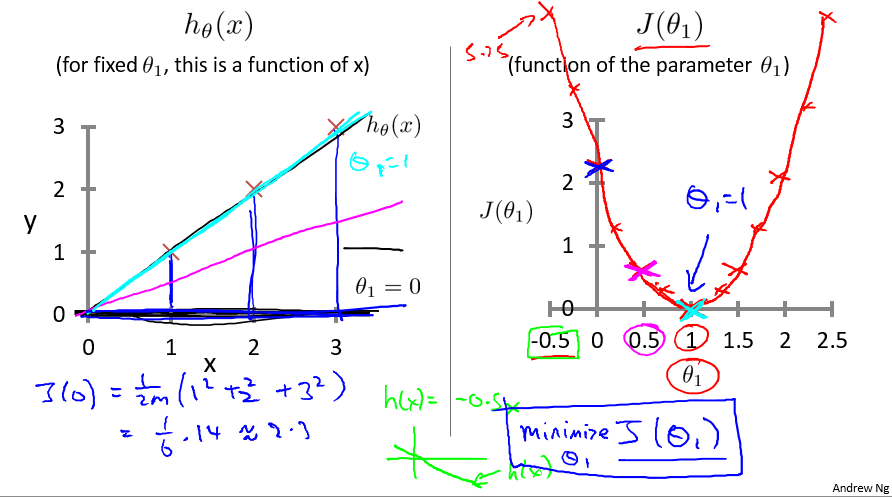
那么,我们可以猜想一下,最快速的方法求 J(θ1) 的最小值,就是求其关于 θ1 的导数。
四、代价函数 直观展现 II(Intuition II)
在 Intuition I 中,为了求解方便,我们残忍地抛弃了 θ1 ,但是 θ0 和 θ1 同等重要。现在,我们要将 θ0 捡回来,并加以悉心照料。
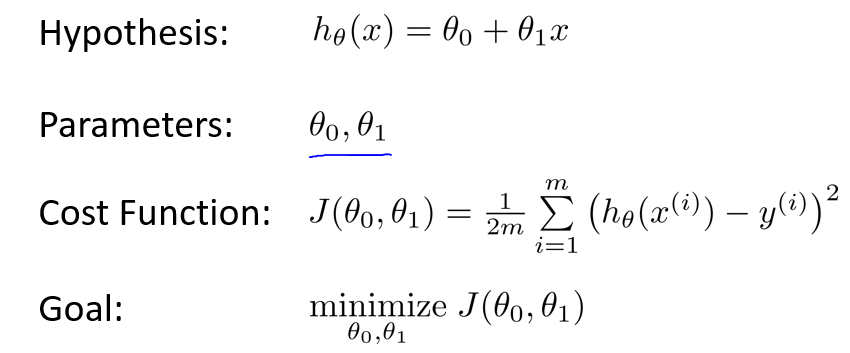
现在假设 θ0 = 50, θ1 = 0.06 ,得到直线如下图所示:
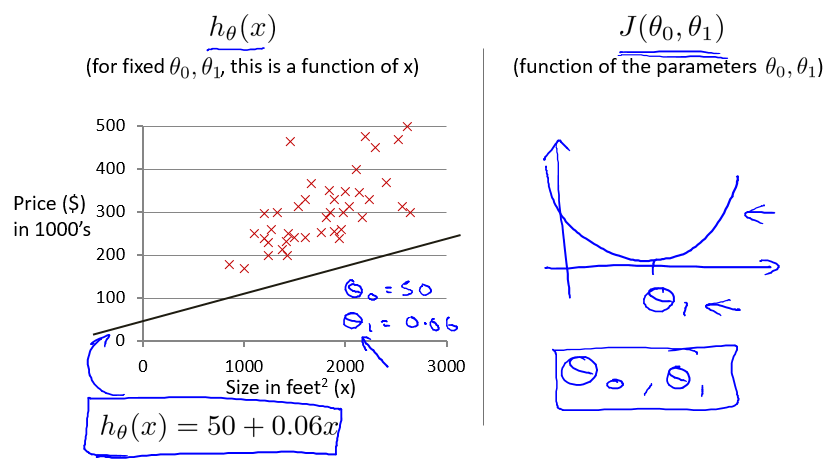
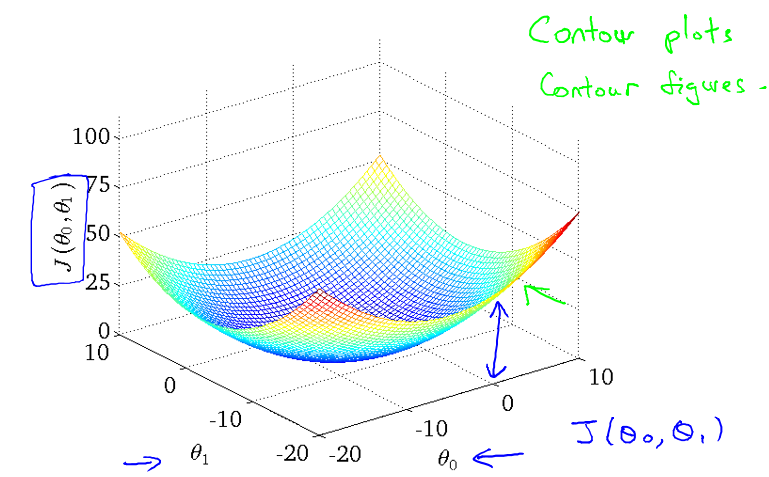
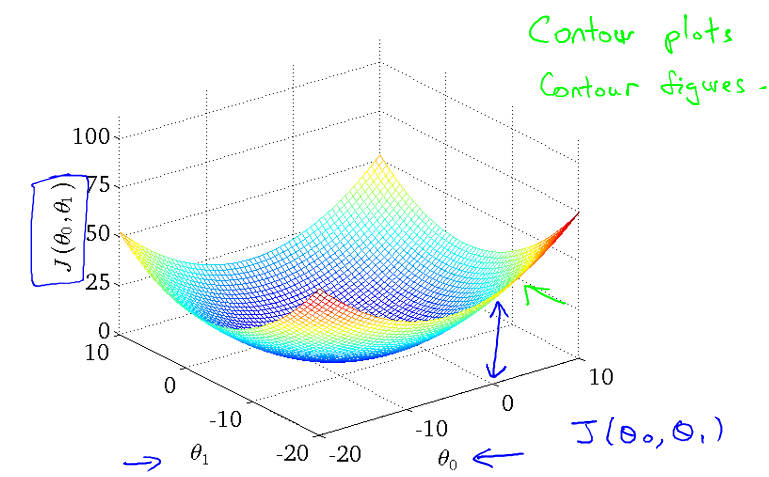
在 Intuition I 中,J(θ1) 是关于 θ1 的二次函数。由于现在有两个参数 θ0 和 θ1 ,J(θ0, θ1) 利用 matlab/octave 绘图结果表示如下:

但是,这样的显示,尽管我们能够大致的了解到 J 的最小值所在的位置,但是并不太明显,因此,利用等值线的显示方法,可以将 θ1 ,J(θ0, θ1) 更加直观地展现。
等值线:处在该曲线上的所有点的值都相等,且越往内值越小。
例如,对于下面的 hθ(x) ,其 J(θ0, θ1) 的值在等值线中表示如图中红 X 所示:
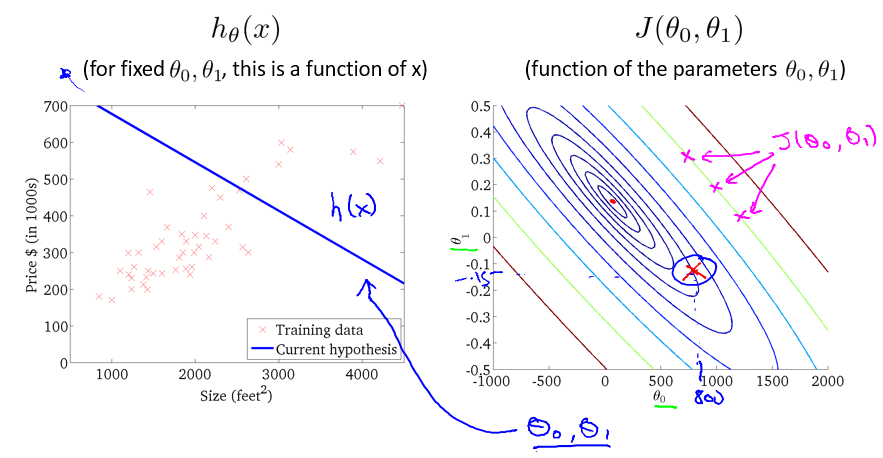
选取另外的 θ 值,J(θ0, θ1) 的值更加接近最小值:
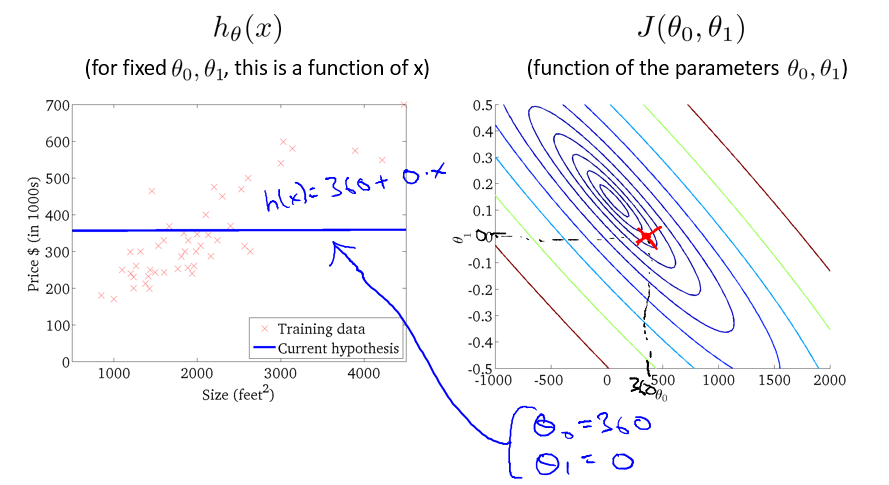
选取到合适的 θ 值后,J(θ0, θ1) 的值基本完全接近最小值:

五、梯度下降法(Gadient Descent)
现在我们已经知道,需要选择适当的 θ ,以将 J(θ0, θ1) 最小化,如下图所示:

在平面内,θ 的取值有无限种, 从而 J(θ0, θ1) 所表示的函数有无限种可能,我们不可能仅仅用猜测的方法得到所需要的结果。因而,寻求一种求 J(θ0, θ1) 最小值的方法极其重要。
典型的方法就是 梯度下降 法,如下图所示:
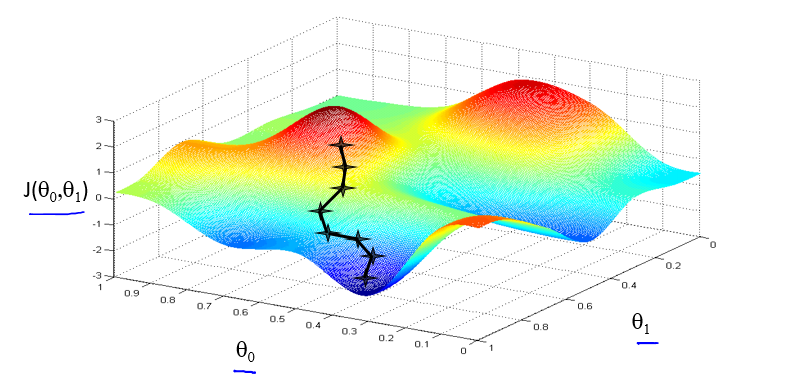
假设你现在站在一个山坡上,想要以最快的方法到达山底,通常我们会选择每一次向下迈一步,在多步之后到达山底。然而,有一种情况需要考虑,就是多多个山底的情况,在你选择不同的出发点时,可能会到达不同的山底:
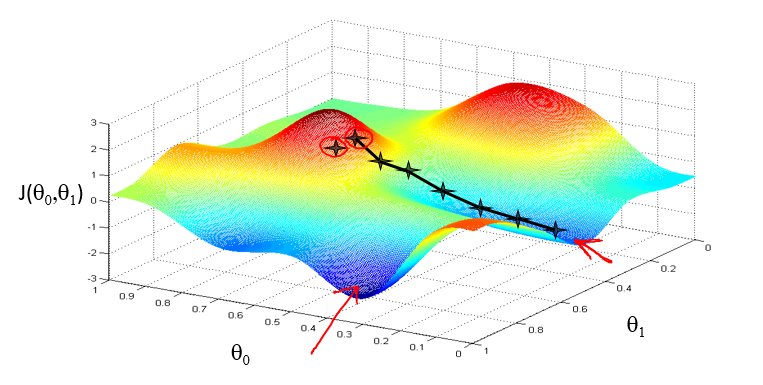
我们所说的山底,就是 J(θ0, θ1) 的一个局部最优解,有时候局部最优解并不能代表全局最优解。庆幸的是,在文中的例子中,我们选择的假设函数 hθ(x) 是一条直线,从而 J(θ0, θ1) 是一个二次函数,它只有一个最优解,利用梯度下降方法可以很好的解决问题。
那么,如何迈每一步,也就是说如何执行梯度下降算法?其执行过程如下:

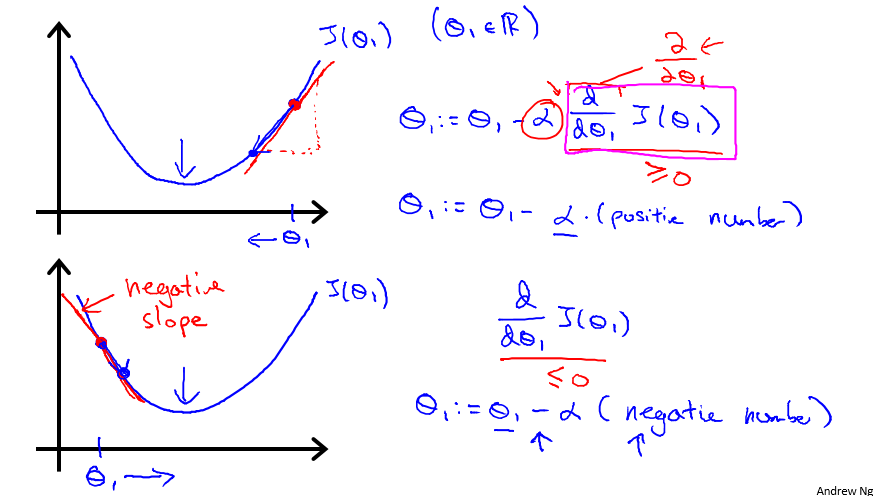
对于 θj ,先求 J(θ0, θ1) 关于 θj 的偏导,在乘以 α(称为学习率),再用 θj 减去这个值,相当于所有的 θj 都在一定程度上向最小值所表示的点迈进,这在图中就表示 J(θ0, θ1) 向下迈了一步。一直重复这一步骤,直到 θ0 和 θ1 基本不变即结束。

此处,需要注意以下几点,非常重要:
1. := 符号表示赋值,= 符号表示求真;
2. α 表示学习率,决定了梯度下降的步子迈得有多大,α > 0;
3. 所有的 θ 值必须同步更新。
六、梯度下降 直观展现(Gradient Descent Intuition)
我们知道了梯度下降方法的相关概念,现在进行直观的展现以解释梯度下降的执行过程。梯度下降算法如下:

为了更方便的解释,先让 θ0 := 0,这样 J 简化为关于 θ1 的一元二次函数。当 J(θ1) 关于 θ1 的导数大于0时, θ1 左移, J(θ1) 下降。当 J(θ1) 关于 θ1 的导数小于0时, θ1 右移, J(θ1) 仍然下降。
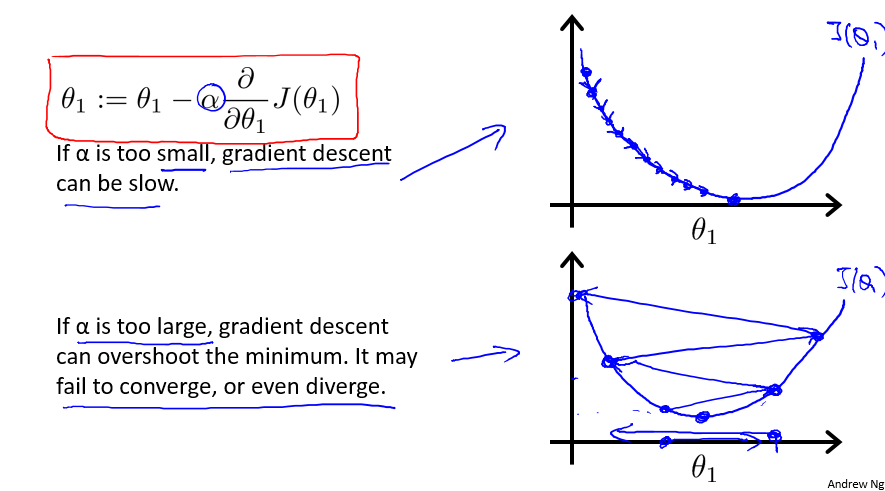
那么问题来了。 如果迈的步子太小,J(θ1) 每次只降低一点点,什么时候才能到最底部? 如果迈的步子太大, J(θ1) 越过了最小值到达另一边,会出现什么情况?
这两个问题,跟学习率 α 有着极大的关系。如果 α 太小,梯度下降算法将会相当慢。如果 α 太大,梯度下降可能越过最小值,导致不收敛,甚至发散。
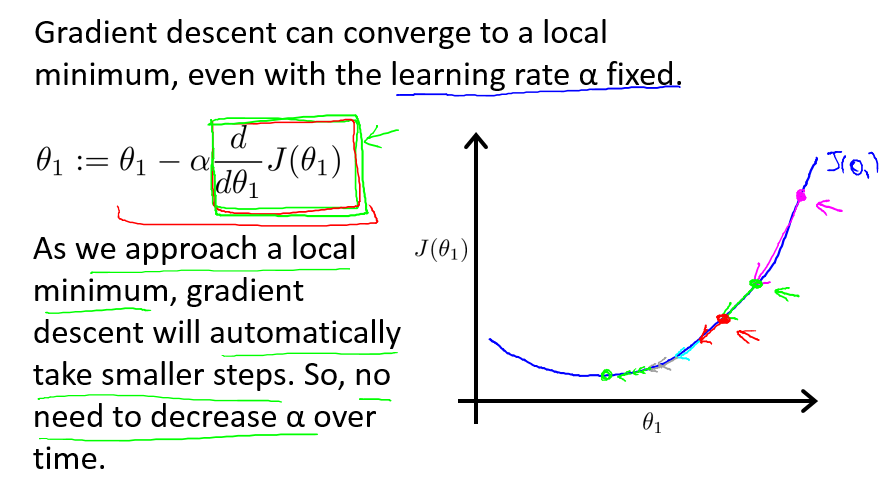
让人欣慰的一件事是,在大部分的问题中,随着 θ 逐渐靠近最优解,J(θ) 关于 θ 的偏导的绝对值将会更小,也就是说曲线更加平滑。这意味着 θ 的减少或增加逐渐缓慢,也就意味着,J(θ) 的减小将会逐渐缓慢。因此,我们并不需要在每一步去降低 α 的值。
七、线性回归梯度下降(Gradient Descent for Linear Regression)
现在,了解了梯度下降与线性回归,现在需要将它们进行结合,以求解本文中的房价问题的单变量线性回归模型。

对于线性回归模型,由于可以求 J(θ) 关于 θ 的偏导:
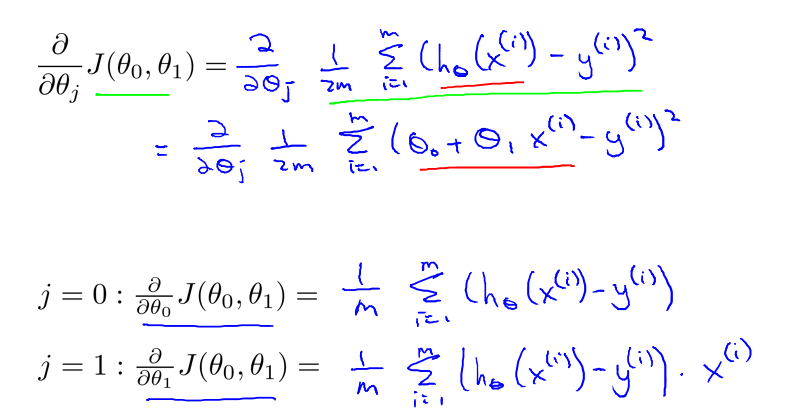
因而,梯度下降方法转化为如下形式(θ0 和 于 θ1 必须同步更新):

而且,由于 J(θ0, θ1) 的形状是一个碗形的,因此梯度下降最后将收敛到最小值: