Chi2 - 高效抽取分类特征词
本文介绍使用卡方检验有效抽取行业分类关键词的方法


转载请注明出处: https://gaussic.com/chi2-keyword-extraction/
用朴素贝叶斯做文本分类的原理是,计算文本中出现的词属于某一类的联合概率。
其中,一个词在不同分类下的概率是不同的,例如,「基金」这一词属于「投资」类的概率比属于「餐饮」类的概率要高,「火锅」这个词则相反。
那么,我们是否可以预先计算出一个分类下所有词的概率呢?答案是:可以!
词频统计
我们首先想到的是词频。首先使用分词工具,将文本切分为合适的词组形式。当前工业界使用较为广泛的是「jieba分词」,它在保障准确性的同时也能达到较快的分词速度。
import re
import jieba
def segment(sentence, cut_all=False):
sentences = re.sub('[\n\u3000。,,;\??\u00a0”“\(\)()、\-—:/《》!~【】%\d+]', ' ', sentence)
sentence = [x for x in jieba.cut(sentences, cut_all=cut_all) if x != ' ']
return sentence
segment('上海星巴克咖啡经营有限公司淮海中路五店')
# 分词结果:
['上海', '星巴克', '咖啡', '经营', '有限公司', '淮海中路', '五店']
我们以「THUCNews 新闻数据集」为例,抽取财经类5000篇文档,统计各词的词频:
import os
from collections import Counter
ROOT_DIR = '/Users/gaussic/data/THUCNews'
category = '财经'
word_cat_cnt = Counter() # 记录词频
for i, fname in enumerate(os.listdir(os.path.join(ROOT_DIR, category)), 1):
fname = os.path.join(ROOT_DIR, category, fname) # 文件名
sentence = open(fname, 'r', encoding='utf-8', errors='ignore').read()
word_cat_cnt.update(segment(sentence)) # 更新词频
if i == 5000:
break
word_cat_cnt.most_common(30)
# 输出top30词
[('的', 148410),
('基金', 51183),
('在', 33436),
('.', 30862),
('了', 21543),
('市场', 20365),
('是', 20228),
('和', 18462),
('月', 17807),
('公司', 14630),
('也', 14405),
('年', 13635),
('为', 13414),
('将', 12783),
('投资', 11926),
('有', 11730),
('对', 11092),
('日', 9663),
('中', 9377),
('期货', 9356),
('而', 9326),
('元', 8809),
('但', 8460),
('上', 8081),
('价格', 7537),
('从', 7415),
('等', 6846),
('目前', 6841),
('上涨', 6790),
('中国', 6688)]
值得一提的是,像「基金、投资、期货、价格、上涨」这些词正如我们所预期的排在了前面,它们是将一篇文档划分为财经类的重要参考。
但是,像「的、在、了、是、和」这些词,它们几乎出现在所有类型的文章中,对分类不提供任何的参考价值,甚至会对机器分类产生极大的干扰。
解决这一问题的一种方法是维护一张过滤词表,把不需要的词从词频排序中过滤掉,自然语言处理称它们为「停用词」。但是,随着数据量的增大,所需要过滤的词会越来越多,人工干预的成本会越来越高,显然不利于后期的维护。
TF-IDF关键词抽取
另一种方法,就是我们通常使用到的TF-IDF关键词抽取算法。它的原理很简单:
- 如果一个词在某个分类下出现的频率很高,同时在所有文档出现的频率也很高,那么这个词大概率是没有意义的,正如前面出现的「的、在、了」等;
- 如果一个词在某个分类下出现的频率很高,而在其他类中出现的频率很低,那么这个词对于这个行业很关键,如「财经」类中的「基金、投资」,「体育」类中的「篮球、比赛」等;
- 如果一个词在所有的分类下出现的频率都很低,那么它为分类带来的参考价值不大,可以适当剔除,如生僻词、个别人名等。
有关TF-IDF的原理与实现可以看这篇:基于特定语料库的 TF-IDF 关键词提取实现
显而易见的,这一结果相比词频统计有了极大的提升。首先,停用词问题得到了极大程度的解决。其次,一些低频词的权重得到了提升,如「ETF、QDII、A股」三个词频较低但非常明显的财经类词。
需要注意的是,部分词可以同时是其他分类下的关键词,如「公司、吨、元、经理、合约、大豆」等。单纯将它们视作某一行业的关键词容易造成分类的混淆。需要适当降低它们的权重。
Chi2 - 卡方检验
卡方检验的本质,是检验两个变量之间有没有关系。
在文本分类的特征选择阶段,一般使用「词t与类别c不相关」来做原假设,计算出的卡方值越大,说明对原假设的偏离越大,我们越倾向于认为原假设的反面情况是正确的。
选择的过程为每个词计算它与类别c的开方值,从大到小排个序,取前k个即可。
以上面的「基金」为例,我们考虑它与「财经」类的相关性。
| 1. 属于「财经」类 | 2. 不属于「财经」类 | |
|---|---|---|
| 1. 包含「基金」 | 5356 (A) | 2500 (B) |
| 2. 不包含「基金」 | 4644 (C) | 127500 (D) |
基于原假设,「财经」类文章中包含「基金」这一词的比例应该与所有文档中包含「基金」的比例相同,因此,A的理论值应为:
$$
E_{11} = (A+C)\frac{A+B}{N}
$$
实际值与理论值的差值为:
$$
D_{11} = \frac{(A-E_{11})^2}{E_{11}}
$$
分别计算表格中4种情况的差值 $D_{11}, D_{12}, D_{21}, D_{22}$ ,求和即为「基金」与「财经」类文章的卡方结果:
$$
\chi^2{(基金, 财经)} = \frac{N(AD-BC)^2}{(A+B)(C+D)(A+C)(B+D)}
$$
其中,N 是总文档数,A+C 和 B+D 对应财经类和非财经类的文档数,在计算某个词属于某个类别时,它们是固定值,可以忽略。
因此结果简化为:
$$
\chi^2{(基金, 财经)} = \frac{(AD-BC)^2}{(A+B)(C+D)}
$$
可见,当$(AD-BC)^2$越大,$\chi^2$也越大,当前词越有可能属于当前类别的关键词。
我们继续使用「THUCNews」实操一下。
首先,从每个类别载入5000篇文档,并统计以下三个值:
from collections import defaultdict, Counter
categories = ['时尚', '家居', '教育', '股票', '娱乐', '彩票', '社会',
'房产', '星座', '科技', '财经', '时政', '游戏', '体育']
doc_cat_cnt = defaultdict(int) # 每类文档数
word_tot_cnt = Counter() # 每个词出现的文档数
word_cat_cnt = defaultdict(Counter) # 每个词在每个分类下出现的文档数
for cat in categories:
for fname in os.listdir(os.path.join(ROOT_DIR, cat))[:5000]:
doc = open(os.path.join(ROOT_DIR, cat, fname), 'r', encoding='utf-8', errors='ignore').read()
doc = set(segment(doc)) # 注意,在chi2中,每个词在每个文档中只统计一次
word_tot_cnt.update(doc)
word_cat_cnt[cat].update(doc)
doc_cat_cnt[cat] += 1
接下来,使用pandas来批量计算卡方值:
import pandas as pd
import numpy as np
# 词-文档数
word_tot_df = pd.DataFrame(list(word_tot_cnt.items()), columns=['word', 'tot_freq'])
# 词-分类-文档数
word_cat_df = []
for cat in categories:
cur_cat_df = pd.DataFrame(list(word_cat_cnt[cat].items()), columns=['word', 'cat_freq'])
cur_cat_df['cat'] = cat
word_cat_df.append(cur_cat_df)
word_cat_df = pd.concat(word_cat_df, ignore_index=True)
# 双表连接
word_cat_df = word_cat_df.merge(word_tot_df, on=['word'], how='inner')
word_cat_df['doc_cnt'] = word_cat_df['cat'].map(doc_cat_cnt)
word_cat_df[word_cat_df['word']=='基金']
| word | cat_freq | cat | tot_freq | doc_cnt | |
|---|---|---|---|---|---|
| 164871 | 基金 | 6 | 时尚 | 3974 | 5000 |
| 164872 | 基金 | 36 | 家居 | 3974 | 5000 |
| 164873 | 基金 | 56 | 教育 | 3974 | 5000 |
| 164874 | 基金 | 593 | 股票 | 3974 | 5000 |
| 164875 | 基金 | 90 | 娱乐 | 3974 | 5000 |
| 164876 | 基金 | 82 | 彩票 | 3974 | 5000 |
| 164877 | 基金 | 40 | 社会 | 3974 | 5000 |
| 164878 | 基金 | 120 | 房产 | 3974 | 5000 |
| 164879 | 基金 | 11 | 星座 | 3974 | 3578 |
| 164880 | 基金 | 109 | 科技 | 3974 | 5000 |
| 164881 | 基金 | 2707 | 财经 | 3974 | 5000 |
| 164882 | 基金 | 63 | 时政 | 3974 | 5000 |
| 164883 | 基金 | 44 | 游戏 | 3974 | 5000 |
| 164884 | 基金 | 17 | 体育 | 3974 | 5000 |
N = sum(doc_cat_cnt.values()) # 总文档数
def get_chi2(x):
A = x['cat_freq']
B = x['tot_freq'] - x['cat_freq']
C = x['doc_cnt'] - x['cat_freq']
D = N - x['tot_freq'] - x['doc_cnt'] + x['cat_freq']
return np.round((A*D - B*C)**2 / (A+B) / (C+D), 4)
# 计算chi2值
word_cat_df['chi2'] = word_cat_df.apply(get_chi2, axis=1)
# chi2原始值较大,可使用min-max逐行业归一化
cat_max = dict(word_cat_df.groupby('cat')['chi2'].max())
cat_min = dict(word_cat_df.groupby('cat')['chi2'].min())
def get_chi2_norm(x):
return np.round((x['chi2'] - cat_min[x['cat']]) / (cat_max[x['cat']] - cat_min[x['cat']]), 4)
# 计算chi2_norm值
word_cat_df['chi2_norm'] = word_cat_df.apply(get_chi2_norm, axis=1)
# 按照行业和chi2逆序排列
word_cat_df.sort_values(by=['cat', 'chi2'], ascending=False, inplace=True)
输出4类新闻的TOP20关键词:
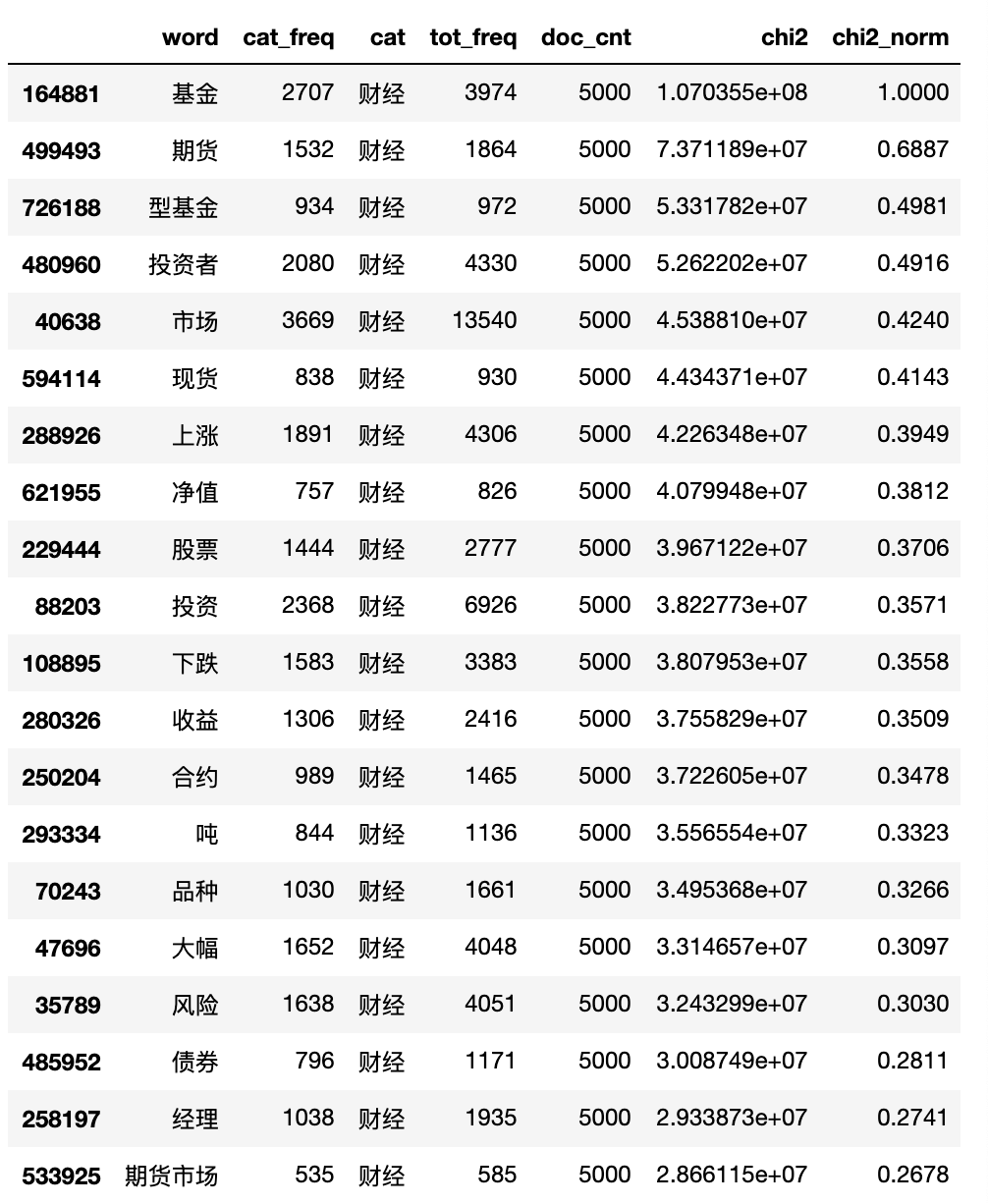
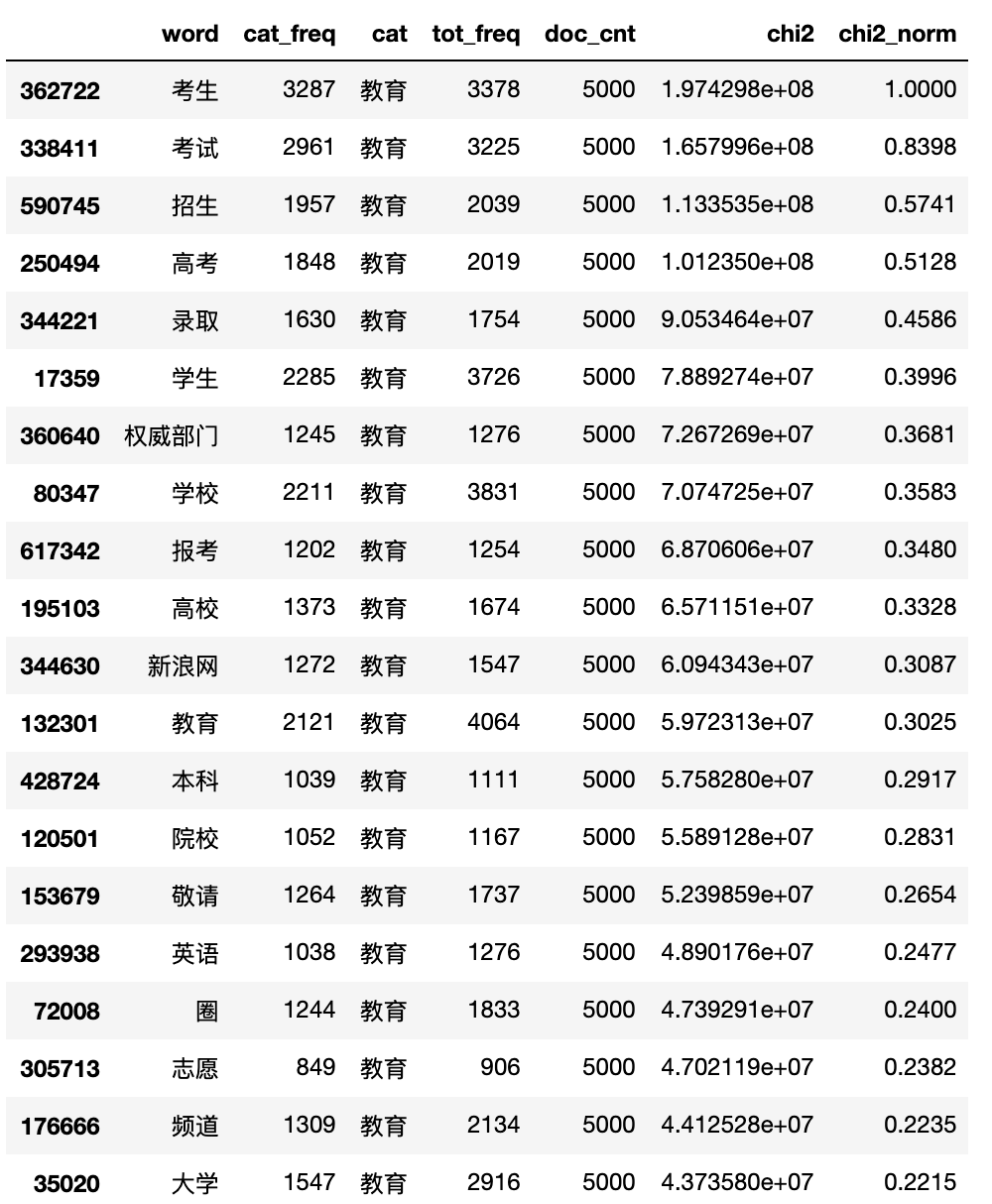
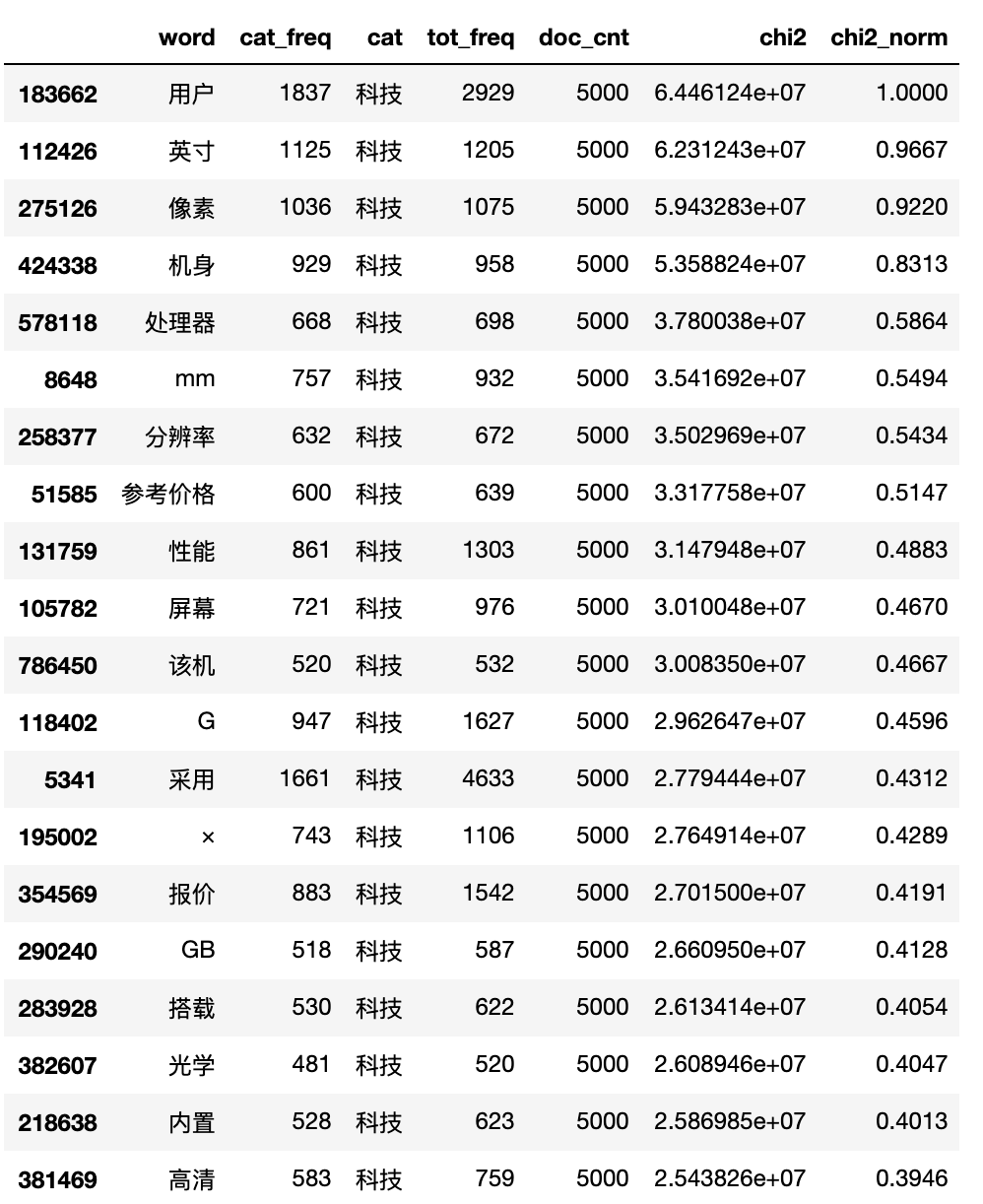
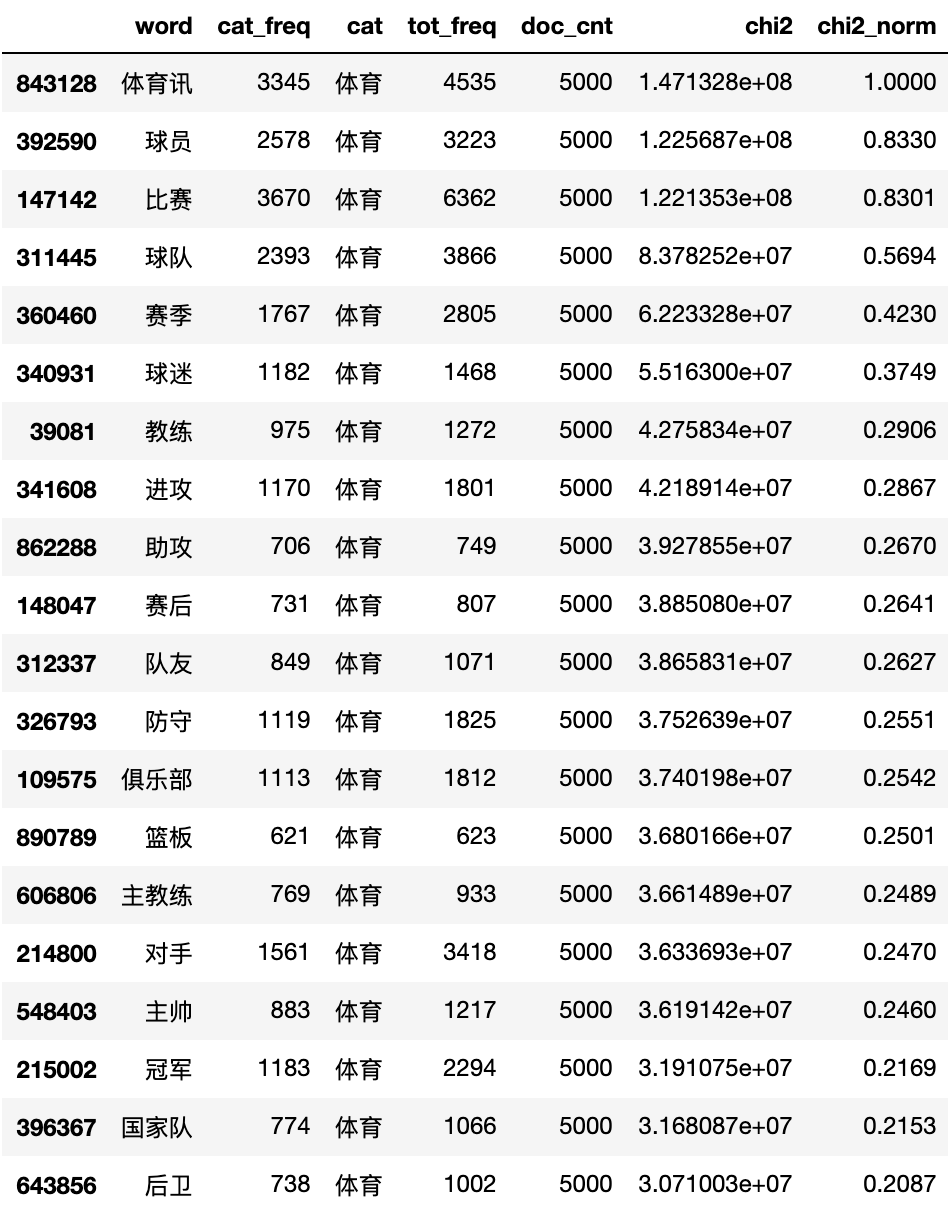
相比TF-IDF,Chi2卡方检验更大程度的较低了类别混淆词的权重,并且一些整体词频较低但在当前行业出现次数较高的词的权重得到了提升,这使我们更容易发现一些分类中的新词。
值得一提的是,由于Chi2只统计词所出现的文档数,而不考虑在每一篇文档中出现的次数,这可能会将低频词的权重过度放大,影响对高频词的判断。
当然,在一些特定的场景,如短文本分类,Chi2的低频词缺陷问题便不复存在。
例如商户名称分析,如何从多个行业的千万级商户名录中,抽取各个行业的关键词,Chi2不失为一种及其有效的方法。
在抽取完商户关键词后,我们可以将商户行业进一步细分,如餐饮继续划分为火锅、甜品、饮品、中餐、西餐等等,甚至可以挖掘出大量的品牌名称。
试想,如果我们拥有大量的客户交易数据,使用行业关键词抽取方法对客户的交易商户信息进行细分后,是否就能充分挖掘到客户的消费偏好,而进行更加定制化的推荐呢?
答案是不言而喻的。