从零开始做歌词生成器 - 1 - 歌词清洗与分析
上一篇中详述了歌词的抓取部分,大约抓取到了 3 万 7 千多篇歌词,未经过任何清洗。在这一篇中,需要对歌词做一些简单的清洗和分析工作。


转载请注明出处:https://gaussic.com/lyric-generation-2/
接上一篇:从零开始做歌词生成器 - 0 - 抓取网易云 3 万首歌词
上一篇中详述了歌词的抓取部分,大约抓取到了 3 万 7 千多篇歌词,未经过任何清洗。在这一篇中,需要对歌词做一些简单的清洗和分析工作。
代码暂时放在这个 repo 里,到后面整合到完整的系统中:gaussic/crawl_scripts
环境依赖:
jieba、gensim、pandas
前言
如下图所见,这些歌词中包含了中、韩、日、英四种语言,中文还分繁、简。以及时间线、工作人员等等。由于是针对中文的歌词生成器,因此需要过滤掉大量的文本。
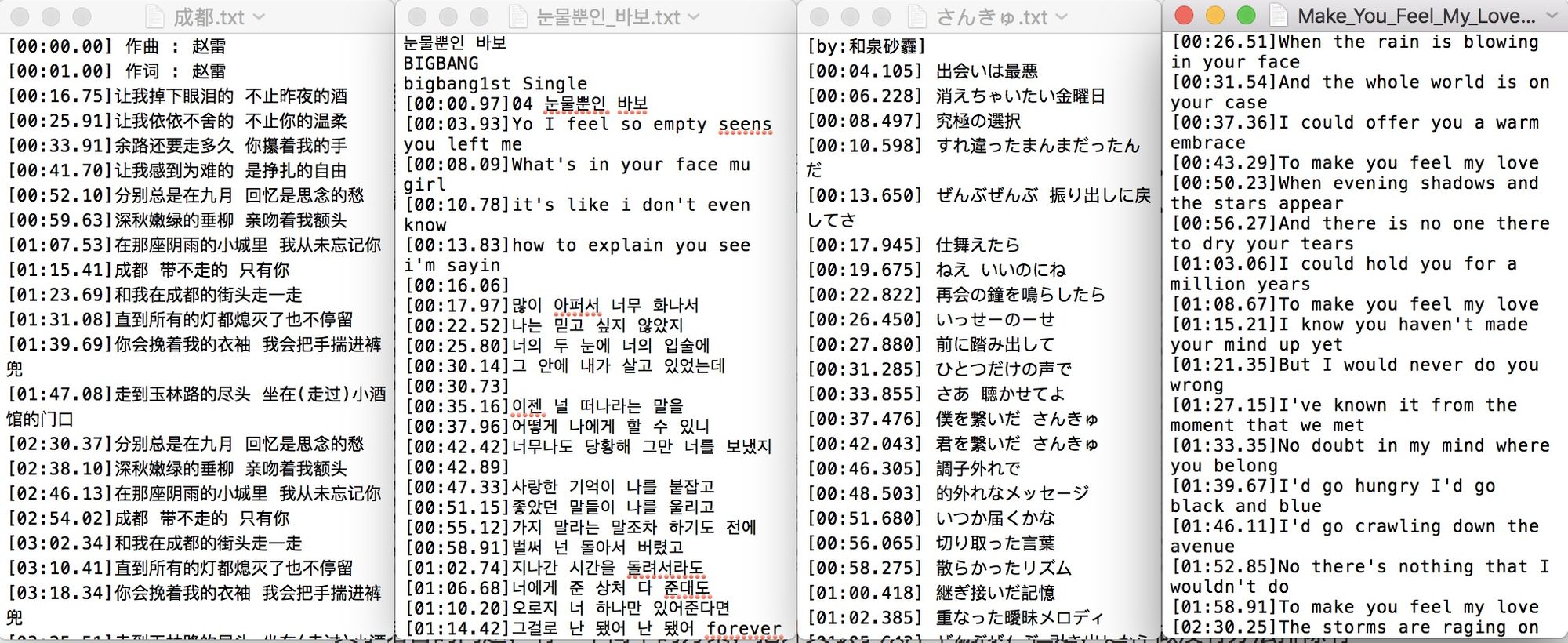
关于时间线、工作人员,基本都有固定的模式,可以使用正则表达式去除。
关于语言的问题,有一个简单的方案,把外文歌手从库中删除,这样做没有办法排除有些华语歌手唱的外文歌曲,以及一些带有中文翻译的歌曲,治标不治本。另一个解决方案,是根据中文字符区间,用正则表达式来处理,这样似乎更加合情合理。
此外,为了缩小词汇表的大小,减少模型参数,将繁体字转换为简体字,这个可以通过繁简对照表完成。
另外一个问题,同一个歌手的一首歌会有多个不同的版本(Remix,Live 等等),但是歌词是相似的,需要尽量的只保留一个版本,因此需要去重。当然,这个步骤是可选的,保存一定的重复对模型其实影响并不大。对于去重,需要计算各文档相似度,然后再去除相似度高的文档。
关于以上步骤的实现,我们逐步叙述。
初步清洗
大部分的时间轴和额外信息,被包在 [] 中,可以把这一部分直接去除。此外,还有一工作人员的信息,基本(并非全部)都有固定的格式,可以根据几个关键词去除大部分。
关于语言判断,中文字符区间是 \u4e00-\u9fa5,统计符合该区间内字符数量,如果超过 8 成都是中文,则判断为中文。这个百分比可以调整,因为还存在一些双语歌词。
使用正则表达式,初步清洗的函数如下:
def open_file(filename, mode='r'):
return open(filename, mode=mode, encoding='utf-8', errors='ignore')
def is_chinese(text):
text = ''.join([x.strip() for x in text.split('\n')])
res = ' '.join([r for r in re.findall(r"[\u4e00-\u9fa5]+", text)]) # 中文字符区间
return len(res) >= 0.8 * len(text) # 8成以上是中文
def clean_text(filename):
text = open_file(filename).read()
text = re.sub(r"\[.*\]", "", text) # 过滤时间轴
text = re.sub(r"作词.*\n", "", text) # 过滤掉工作人员
text = re.sub(r"作曲.*\n", "", text)
text = re.sub(r"编曲.*\n", "", text)
text = re.sub(r"演唱.*\n", "", text)
text = re.sub(r"制作人.*\n", "", text).strip()
return text
繁简转换
部分的粤语歌繁体居多,因此可以考虑将繁体转换为简体,降低词汇表大小。
总结了一张对照表,格式如下:
瀋 沈
畫 划
鍾 钟
靦 腼
餘 余
鯰 鲇
鹼 碱
㠏 㟆
...
我们需要读取这张表,再将初筛后的文本转换为简体,需要两个辅助函数:
def read_convert_words(filename):
"""读取繁简字体转换表"""
tr_to_cn = {}
with open_file(filename) as f:
for line in f:
key, value = line.strip().split()
tr_to_cn[key] = value
return tr_to_cn
def convert_tr_to_cn(sentence, tr_to_cn):
"""繁简转换"""
cn_s = ''
for x in sentence:
if x in tr_to_cn:
x = tr_to_cn[x]
cn_s += x
return cn_s
接下来,就是遍历所有目录下的所有歌词文档,然后一片片处理再转存:
base_dir = "data"
new_dir = "data_clean" # 保存到新的目录下
if os.path.exists(new_dir):
shutil.rmtree(new_dir)
os.mkdir(new_dir)
cnt = 0 # 编号
tr_to_cn = read_convert_words('tr-cn.txt')
for cur_dir in os.walk(base_dir): # 遍历所有文档
for filename in cur_dir[2]:
try:
file_dir = os.path.join(cur_dir[0], filename)
data = clean_text(file_dir)
if is_chinese(data) and len(data) >= 200: # 中文,200字符以上
data = convert_tr_to_cn(data, tr_to_cn) # 转换为简体
filename = convert_tr_to_cn(filename, tr_to_cn)
filename = ''.join(filename.split('.')[:-1])
new_file = filename + ' - ' + str(cnt) + '.txt' # 防止重名覆盖,打个编号
open_file(os.path.join(new_dir, new_file), 'w').write(data) # 汇总写入新目录
cnt += 1
except:
pass
这里只保留清洗之后 200 字符以上的歌词,处理完毕大约剩下 16000 多篇。
经过初筛后和繁简转换后的示例如下:
![lyric-1-2.jpg])(https://gaussic.com/content/images/2020/01/lyric-1-2.jpg)
{kind=link}
相比原始的数据,已经干净了许多。
歌词去重
接下来还需要处理歌词重复的问题,查看剩下的文档,发现重复情况还是比较严重的,仅陈奕迅的一首 K歌之王 就出现了 10 次以上。
去重的一个简单思路是提取所有文档的 TF-IDF 特征向量。然后再逐个计算每一篇文档的特征向量与其他所有文档的相似度。如果相似度最高的两篇文档的相似度小于所设阈值,那么说明这篇文档没有出现过。
有一个问题是,这个算法的复杂度是 $O(n^2)$,1.6 万文档计算量过亿,外加每篇文档的相似度对比还需要一定的时间,总体可能需要话费数小时。
另外一种快速的海量文档匹配方法,Simhash,测试之后,发现速度虽然快,但是效果并不让人满意。
再次分析数据,把文档按名称排序后,终于找到了优化方法:
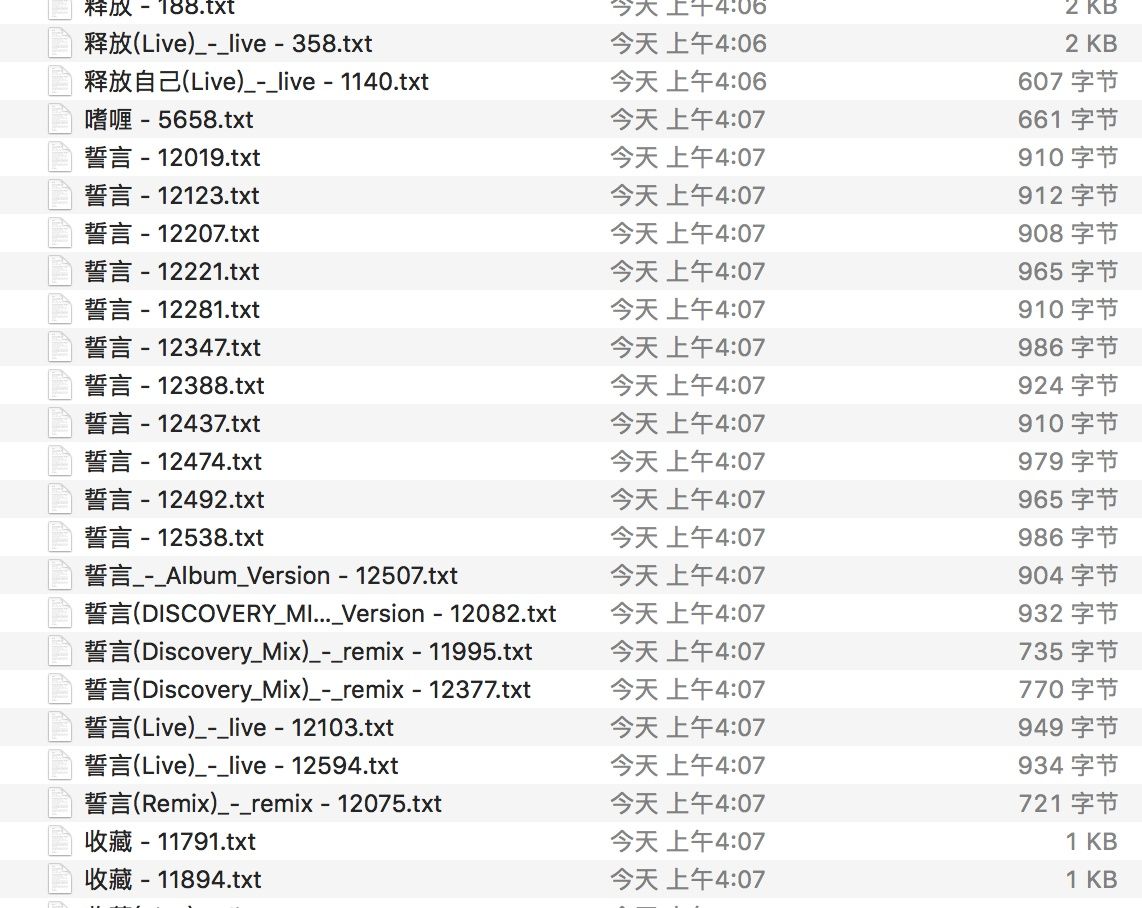
依次打开名称相似的文档,发现其中的内容是几乎相同的。也就是说,我们每次只要对比名称相近的几篇文档就可以了,这样 $O(n^2)$ 变成了 $O(n*k)$,优化相当显著。
在 How do I compare document similarity using Python? 一文中给出了一个使用 gensim 实现文档相似度计算的实例。由于要同时处理多篇文档,在此对其进行了进一步的封装:
# coding: utf-8
import os
import sys
import gensim
import shutil
def open_file(filename, mode='r'):
return open(filename, mode=mode, encoding='utf-8', errors='ignore')
class DocSimilarity(object):
def __init__(self, in_dir):
"""读取所有歌词"""
self.lyrics = [] # 所有歌词
self.fnames = [] # 所有文件名
for fname in sorted(os.listdir(in_dir)): # 排序,让内容相似的更加靠近
self.fnames.append(fname)
self.lyrics.append(list(open_file(os.path.join(in_dir, fname)).read()))
print("原歌词总数:", len(self.lyrics))
self.corpus_pr()
def corpus_pr(self):
"""gensim文档tf_idf计算"""
dictionary = gensim.corpora.Dictionary(self.lyrics) # 文档词汇表
corpus = [dictionary.doc2bow(lyric) for lyric in self.lyrics] # 文档BOW特征向量
tf_idf = gensim.models.TfidfModel(corpus)
corpus = list(tf_idf[corpus]) # 文档TF-IDF特征
self.vocab_size = len(dictionary)
self.corpus = corpus
print("文档TF-IDF特征计算完毕。")
def remove_sim(self, out_dir, max_similarity=0.2, last_k=20):
"""移除相似文档,保存到新目录"""
if os.path.exists(out_dir):
shutil.rmtree(out_dir)
os.mkdir(out_dir)
cnt, yes = 1, 1
c_corpus = [self.corpus[0]] # 第0篇直接放入
open_file(os.path.join(out_dir, self.fnames[0]), 'w').write(''.join(self.lyrics[0]))
for i in range(1, len(self.corpus)):
try:
# 注意,只对比last_k篇文档,而不是所有歌词
sims = gensim.similarities.Similarity('/Users/gaussic/',
c_corpus[-last_k:],
num_features=self.vocab_size)
if sims[self.corpus[i]].max() < max_similarity: # 如果最相似文本的相似度小于阈值
c_corpus.append(self.corpus[i])
open_file(os.path.join(out_dir, self.fnames[i]), 'w').write(''.join(self.lyrics[i]))
yes += 1
cnt += 1
except:
pass
if cnt % 2000 == 0:
print('已处理:', cnt, '保留:', yes)
print("保留歌词数:", yes)
if __name__ == '__main__':
data_dir = sys.argv[1]
docsim = DocSimilarity(data_dir)
# 对比前20篇文档,相似度低于0.2
docsim.remove_sim('data_unique', max_similarity=0.2, last_k=20)
运行上述代码,原先的 1.6 万文档经过去重后剩余约 5800 篇,且用时不到 5 分钟,效果提升显著。
整合所有歌词
在经过以上清洗之后,数据应该算比较干净了。为了方便后面的训练和测试,现在把所有独立的文档分词并整合到一个文档中,做进一步的预处理。
分词使用jieba分词工具,每一行分词后,每个词以空格隔开。
需要注意的 3 点是:
- 部分歌词前部和后部仍然有一些噪声,考虑直接扔掉前 3 行和后 3 行。
- 分词后列表中存在大量空格和空字符,可以结合
join()和split()去除。 - 一行歌词太长和太短都会对模型的训练造成一定的影响,因而只保留适当长度的行。
import os
import jieba
jieba.enable_parallel(10) # 并行分词
base_dir = 'data_unique'
def open_file(filename, mode='r'):
return open(filename, mode=mode, encoding='utf-8', errors='ignore')
def lyric_group():
lyric_full = open_file('lyric_full.txt', 'w')
for fname in sorted(os.listdir(base_dir)):
data = open_file(os.path.join(base_dir, fname)).readlines()
if len(data) <= 6: # 歌词太短,不要
continue
lyric = []
for line in data[3:-3]: # 前3行后三行都不要
cur_line = list(jieba.cut(line.strip().lower()))
if len(cur_line) >= 30: # 太长不要
continue
lyric.extend(' '.join(cur_line).split())
if len(lyric) >= 5:
lyric_full.write(' '.join(lyric) + '\n')
lyric = []
lyric_full.write('\n') # 每首歌词用空行隔开
lyric_full.close()
整合后的歌词片段示例:
剩下 破折号 有些 人 什么 都 不 知道
好像 一个 人 巨大 的 问号
我 也 不 晓得 他们 如何是好
我 只有 祈祷 不用 别的 标点 和 符号
只 需要 一个 感叹号 不爱 什么 天荒 和 地 老
最 喜欢 一个 感叹号 不管 什么 伟大 和 渺小
只要 只要 出乎意料 感叹 我 的 奇妙
有些 人有 一双 怪 眉毛
皱 起来 好像 一对 括号
他们 越 烦恼 看来 越是 可笑
oh ~ ~ 有些 人 不当 主角
在 人家 的 故事 当 逗号
不 晓得 时候 不 早
我 只有 祈祷 不用 别的 标点 和 符号
只 需要 一个 感叹号 不爱 什么 天荒 和 地 老
最 喜欢 一个 感叹号 不管 什么 伟大 和 渺小
只要 只要 出乎意料 感叹 我 的 奇妙
不论 恋爱 还是 开玩笑 这 是 找 一时 热闹
我要 别人 看到 也 会 说不得 了
不用 别的 标点 和 符号
只 需要 一个 感叹号 不爱 什么 天荒 和 地 老
数据分析
这一步的数据分析,同样为构建模型时的参数选择服务。
首先是总词数和词汇量:
from collections import Counter
lyrics = open_file('lyric_full.txt').read().strip().replace('\n', ' ').split()
counter = Counter(lyrics)
count_pairs = counter.most_common()
print("总词数:", len(lyrics))
print("词汇量:", len(counter))
print("高频词:", count_pairs[:10])
输出:
总词数: 1011164
词汇量: 49280
高频词: [('的', 48193), ('我', 44841), ('你', 41828), ('在', 12436), ('是', 11583), ('了', 10560), ('爱', 8357), ('不', 7975), ('都', 7203), ('有', 6621)]
可以看到,词数达到了 100 万以上,词汇量接近 5 万,前 10 高频词无疑就是汉语常用字。进一步观察:
print(count_pairs[5000])
print(count_pairs[10000])
print(count_pairs[20000])
print(count_pairs[40000])
输出:
('抓不住', 20)
('别爱', 8)
('距', 3)
('严重性', 1)
排行 1 万的词出现 8 次,2 万的词出现 3 次,而 4 万以后的词只出现了 1 词。需要知道,我们的总词量是 100 万以上,这些词频太低的词对模型的影响是微不足道的,因此可以考虑将 1 万以后的这些词替换成 <unk> 标志,词汇表的减小大大降低了模型复杂性。
unk = 0
for i in range(10000, len(counter)):
unk += count_pairs[i][1]
print("UNK所占百分比:{:.3}%".format(unk / len(lyrics) * 100))
取词汇表大小为 1 万,UNK 所占百分比约为 9%,可以进一步地删除部分数据来减小这个量。
count_pairs = counter.most_common(10000)
words, _ = list(zip(*count_pairs))
ws = set(words) # 前1万个词
lyrics = []
for line in open_file('lyric_full.txt'):
line = line.strip().split()
if len(line) == 0:
continue
if len([x for x in line if x not in ws]) <= 0.3 * len(line):
lyrics.append(line)
print(len(lyrics))
在只取 1 万词的情况下,过滤掉 unk 比例超过 0.3 的行,得到 12.5 万行歌词。
import pandas as pd
lengths = list(map(len, lyrics))
lengths = pd.DataFrame(lengths, columns=['lengths'])
print(lengths.describe())
输出:
lengths
count 125940.000000
mean 7.424782
std 2.089210
min 5.000000
25% 6.000000
50% 7.000000
75% 9.000000
max 29.000000
总行数为 125940,每行平均长度 7.42,最小长度为 5,最大为 29,75% 的行长度为 9。
有一些模型在批处理时,需要定长的数据,因此需要把每行 pad 成固定的长度,不足的补 0,太长的裁剪,在这里,我们可以得出,把长度定为 10 左右会比较合理。
这一些分析,不似产品汪所强调的情绪、情节、情怀,但都是对于参数设置非常有意义的分析,在后面的章节会用到。因为我们的目的不单单是通过简单的词频统计来找到歌手的 pattern,而是要创造出一个能够写出兼具各家风格的歌词生成器。
代码暂时放在这个 repo 里,到后面整合到完整的系统中:gaussic/crawl_scripts