从零开始做歌词生成器 - 0 - 抓取网易云 3 万首歌词
本篇和接下来的几篇文章,将从零开始,记录数据的抓取、清洗与分析,到歌词生成模型的构建、训练与分析过程。


本篇和接下来的几篇文章,将从零开始,记录数据的抓取、清洗与分析,到歌词生成模型的构建、训练与分析过程。
要做歌词生成器,首先得有丰富的数据。花了点时间在网易云音乐网页版上面摸索,最后找到了几个页面,几个 API,终于把一整套的流程整理了出来。
转载请注明出处:从零开始做歌词生成器 - 0 - 抓取网易云3万首歌词
抓取流程分析
首先是这个页面:网易云音乐
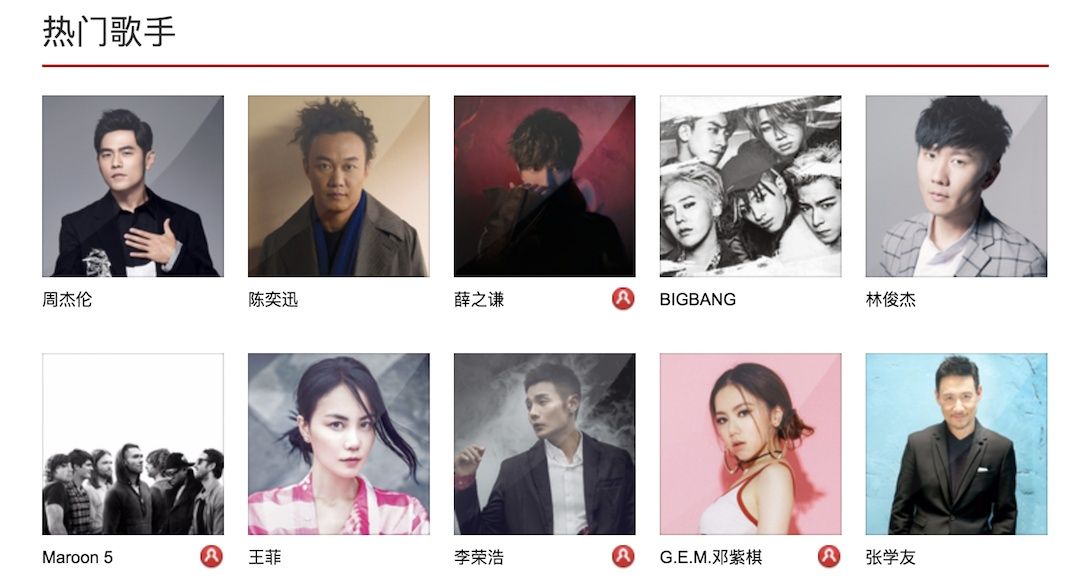
基本上把热门的歌手都涵盖了,如果觉得不满足,还可以点左边的分栏,能找到更多的歌手。
接下来,以周董为例,点击进入周董的页面:周杰伦 - 网易云

周董页面的链接为:
http://music.163.com/#/artist?id=6452
每个歌手都有唯一的 id,使用这个 id 就能找到歌手的页面。不过如果只抓这个链接的话,我们只能抓取到 50 首歌。点击所有专辑,发现每页列出了 12 张专辑。专辑页面的链接如下:
http://music.163.com/#/artist/album?id=6452
可以看到,参数依然是歌手的 id。
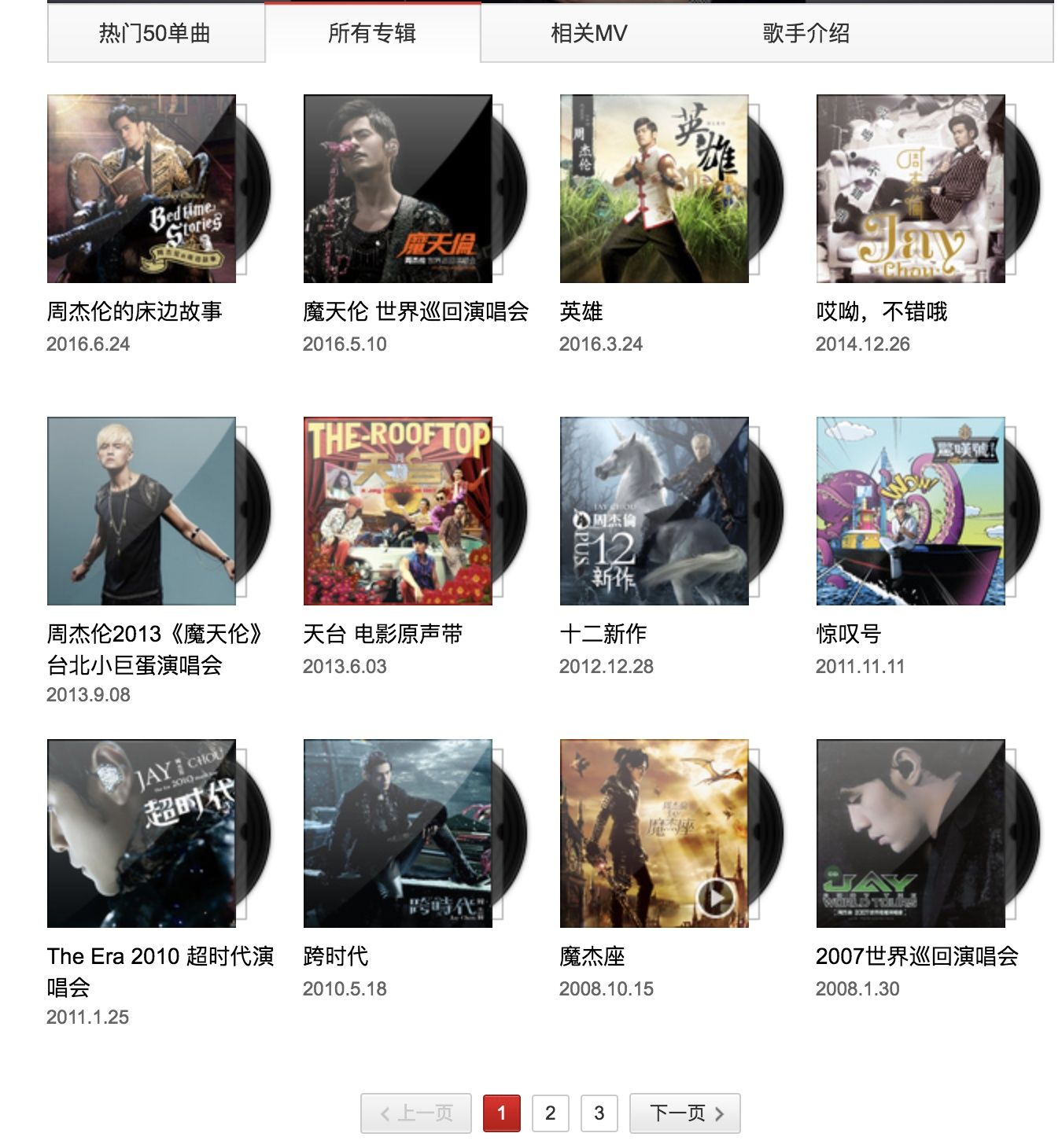
为了不处理分页,可以再传一个 limit 参数:
http://music.163.com/#/artist/album?id=6452&limit=100
这样,所有的专辑都在一个页面显示。再点击进入一张专辑:
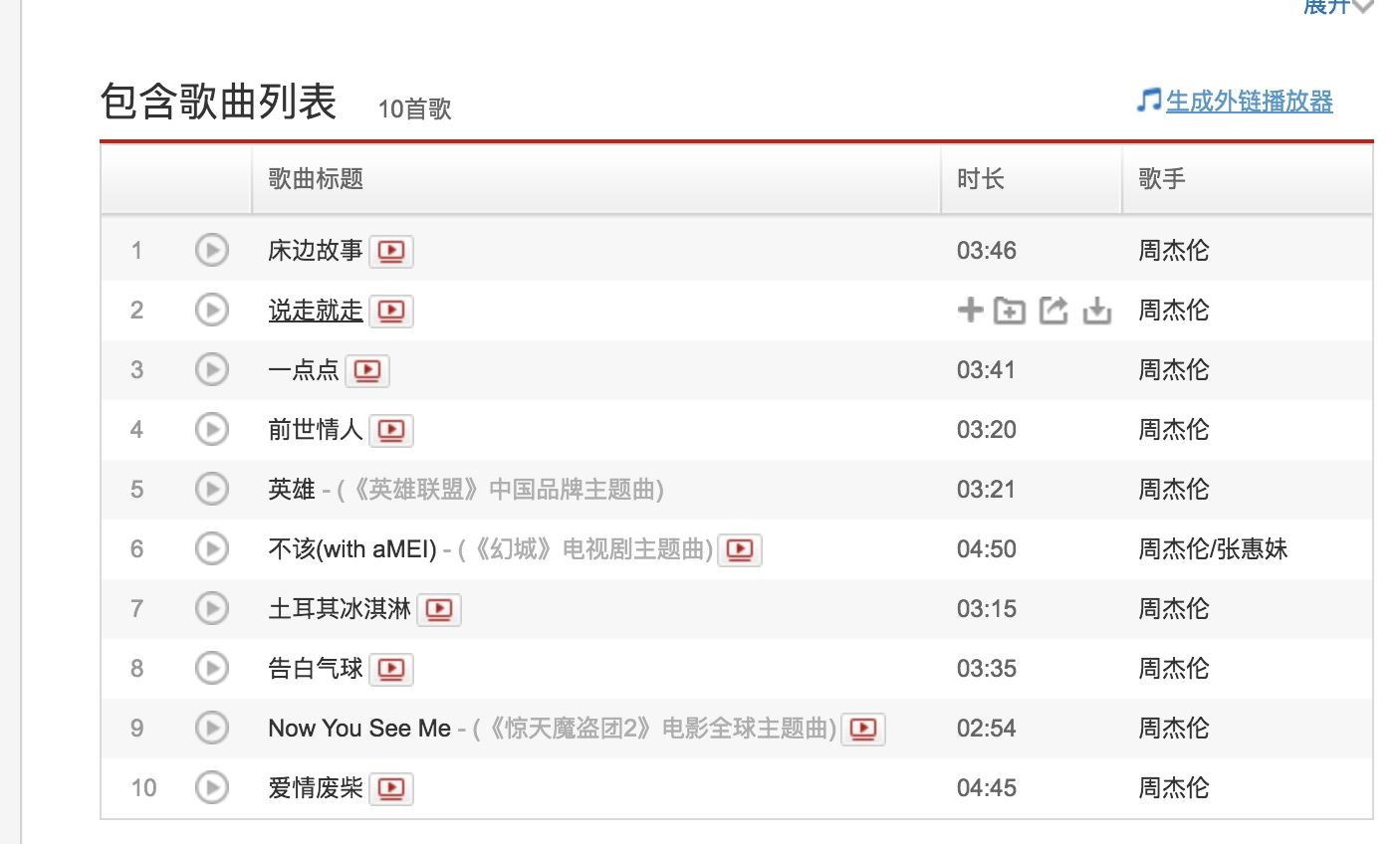
专辑页面链接为:
http://music.163.com/#/album?id=34720827
每一张专辑都有唯一的 id。在点击进入一首歌,发现歌也是由 id 表示的。
http://music.163.com/#/song?id=415792916
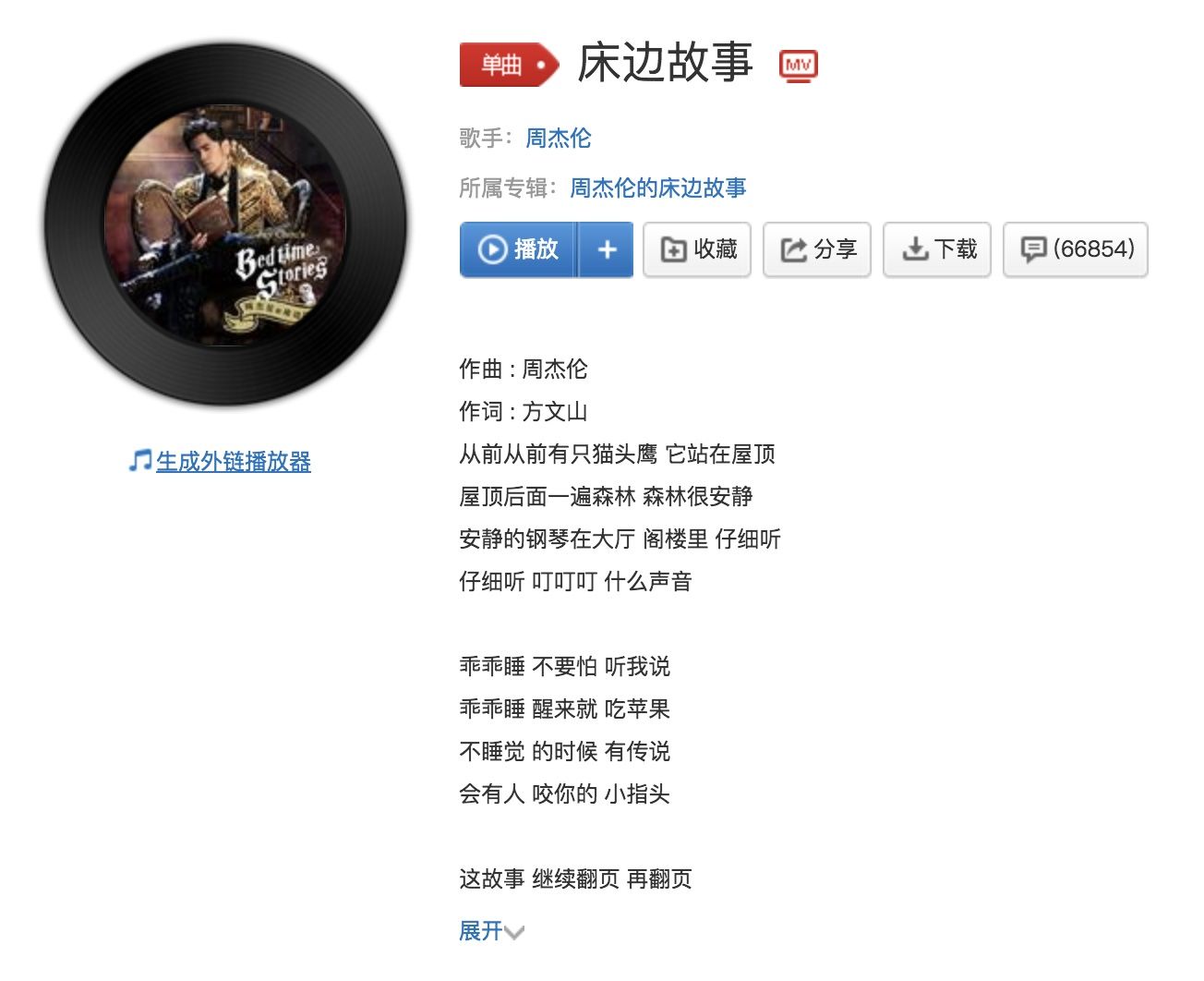
这样,整个的思路就清晰了,先抓取所有热门歌手的 id,再根据歌手 id 抓取其专辑列表,再根据每一张专辑的 id 抓取该专辑下所有歌曲 id,再根据歌曲 id 抓取该歌曲的歌词。
整个从歌手到歌词是一个树形结构。
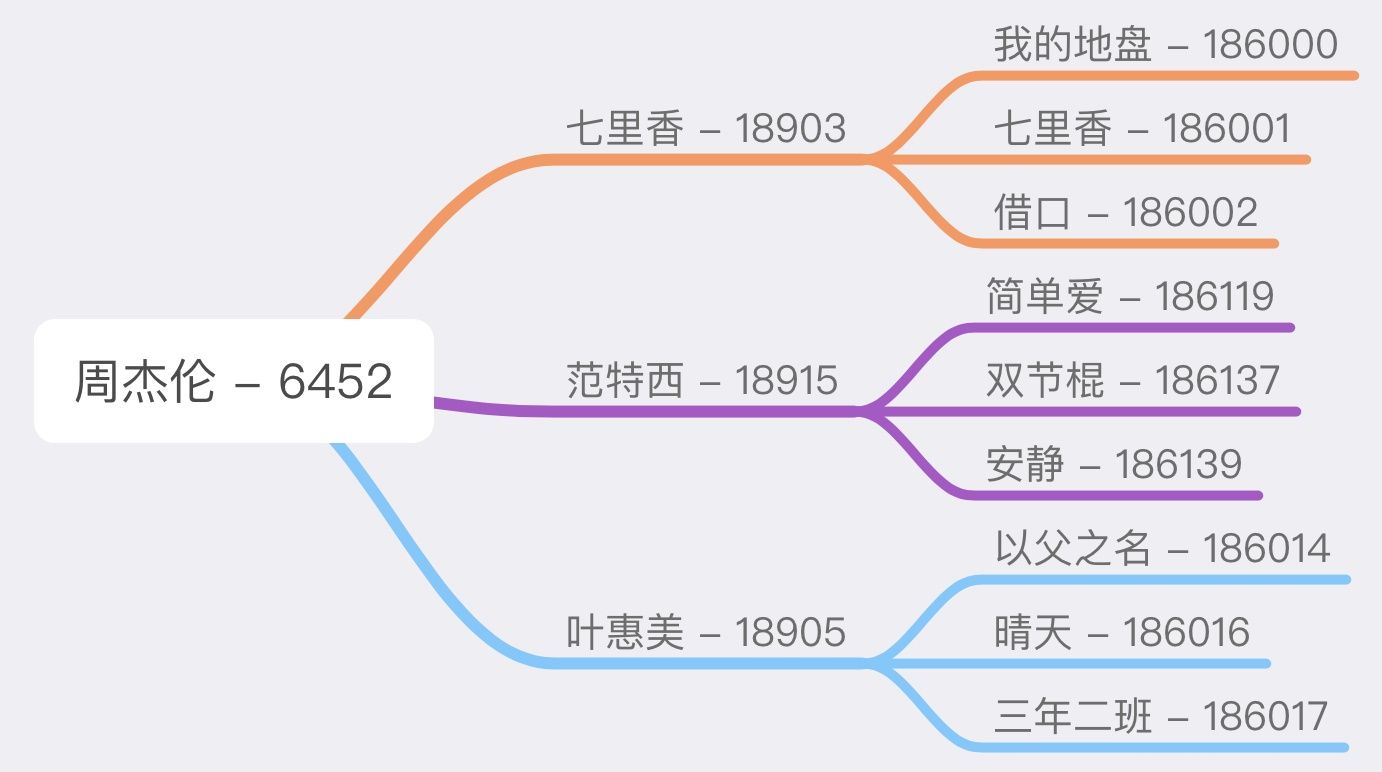
抓取代码
搞明白这个流程,接下来就是抓取的实现,目标是一次性把这些热门歌手的所有歌全部抓取下来。
环境依赖:python 3,requests 2,BeautifulSoup 4。
requests 抓取函数及其他配置:
import os
import json
import requests
from bs4 import BeautifulSoup
base_url = "http://music.163.com"
start_url = base_url + "/artist/album?id={}&limit=100" # 根据歌手的id,抓取其专辑列表
song_url = base_url + "/api/song/lyric?id={}&lv=1&kv=1&tv=-1" # 根据歌曲的id,抓取歌词
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_2) AppleWebKit/537.36 "
"(KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36",
"Referer": "http://music.163.com",
"Host": "music.163.com"
}
def get_html(url): # requests抓取
resp = requests.get(url, headers=headers)
html = str(resp.content, encoding='utf-8', errors='ignore')
return html
首先抓取歌手 id 列表,保存到文件中,注意到这是一个 API,返回的是 JSON 数据,直接访问网页链接是无效的:
def find_artist_ids():
"""只能拿到前100位的歌手ID"""
url = 'http://music.163.com/api/artist/top?limit=100&offset=0'
html = get_html(url)
artists = json.loads(html)['artists']
with open('artists.txt', 'w', encoding='utf-8', errors='ignore') as fa:
for artist in artists:
artist_name = artist['name'].strip().replace(" ", "_")
fa.write(artist_name + ' ' + str(artist['id']) + '\n')
这样,100 位歌手 id 就保存到了 artists.txt 中:
周杰伦 6452
陈奕迅 2116
薛之谦 5781
BIGBANG 126339
林俊杰 3684
Maroon_5 96266
王菲 9621
李荣浩 4292
G.E.M.邓紫棋 7763
张学友 6460
杨宗纬 6066
许巍 5770
蔡健雅 7214
Adele 46487
Bruno_Mars 178059
Coldplay 89365
...
这其中包含中日韩欧美各种语言歌手,可以根据需要自行增删歌手(比如这几篇就只关注中文),不过这篇中,先把全部都抓下来。
然后就是抓取的核心代码:
def crawl_lyrics(art_id):
"""抓取一整个歌手的所有歌词"""
html = get_html(start_url.format(art_id)) # 先抓该歌手的专辑列表
soup = BeautifulSoup(html, 'lxml')
artist = soup.find('h2', id='artist-name').text.strip().replace(' ', '_')
artist_dir = 'data/' + artist
if not os.path.exists(artist_dir): # 歌手目录
os.mkdir(artist_dir)
print("歌手名:", artist)
albums = soup.find('ul', class_='m-cvrlst').find_all('a', class_='msk') # 专辑列表
for album in albums:
html = get_html(base_url + album.get('href')) # 再抓取该专辑下歌曲列表
soup = BeautifulSoup(html, 'lxml')
album_title = soup.find('h2', class_='f-ff2').text.strip().replace(' ', '_').replace('/', '_') # '/'会影响目录
album_dir = os.path.join(artist_dir, album_title)
if not os.path.exists(album_dir): # 专辑目录
os.mkdir(album_dir)
print(" " + artist + "---" + album_title)
links = soup.find('ul', class_='f-hide').find_all('a') # 歌曲列表
for link in links:
song_name = link.text.strip().replace(' ', '_').replace('/', '_')
song_id = link.get('href').split('=')[1]
html = get_html(song_url.format(song_id)) # 抓取歌词
try: # 存在无歌词的歌曲,直接忽略
lyric_json = json.loads(html)
lyric_text = lyric_json['lrc']['lyric']
open(os.path.join(album_dir, song_name + '.txt'), 'w', encoding='utf-8').write(lyric_text)
print(" " + song_name + ", URL: " + song_url.format(song_id))
except:
print(" " + song_name + ": 无歌词, URL: " + song_url.format(song_id))
print()
可以看到,整个代码的核心就是三层结构。保存的时候,也是按照层级结构来保存的。
下面开始抓取:
with open('artists.txt', 'r', encoding='utf-8') as f:
for line in f:
art_id = line.strip().split()[1]
crawl_lyrics(art_id)
整个的代码,加上空行,加上输出提示,加上异常处理,不到 80 行。抓取到的示例如下:
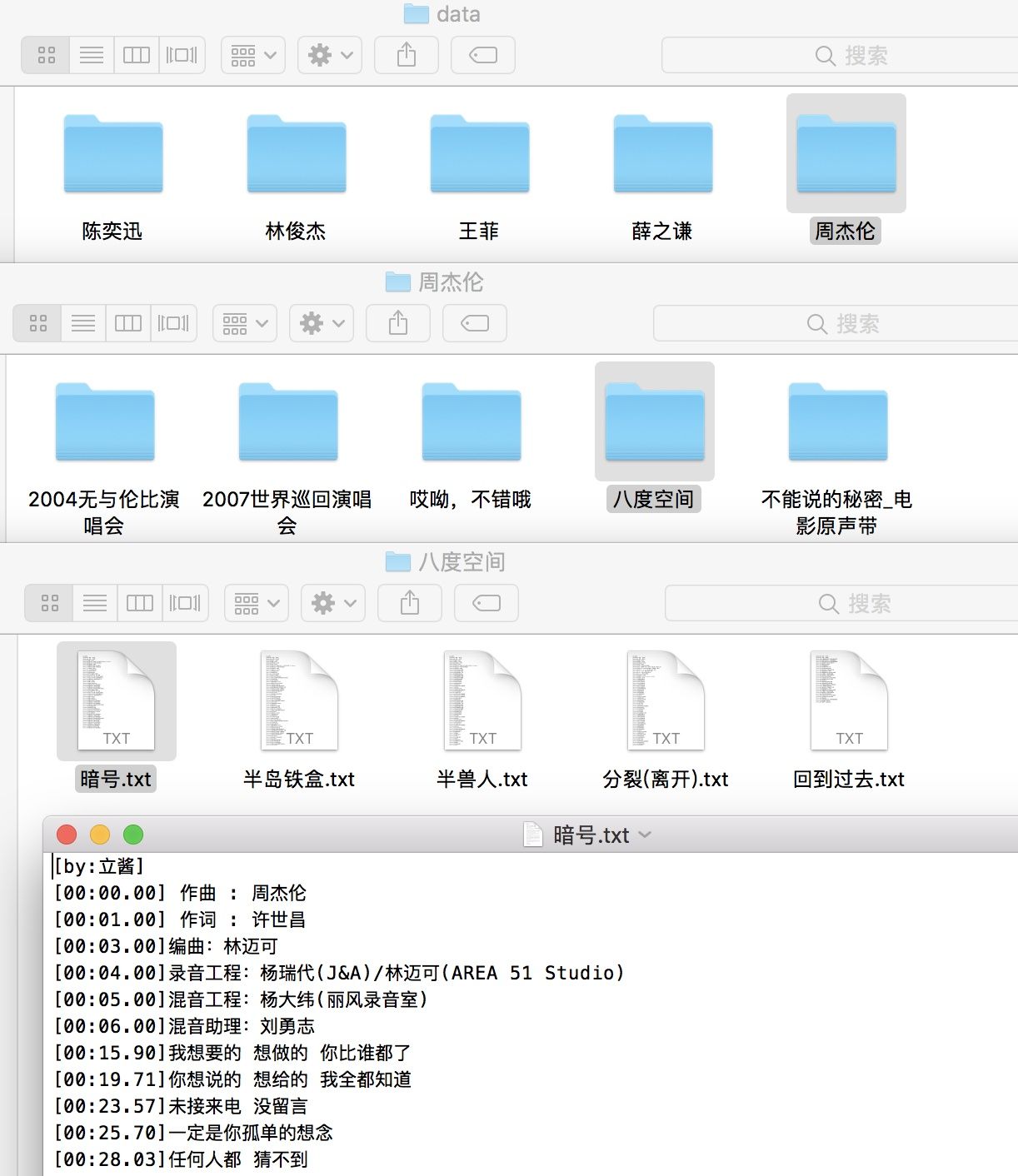
整个 100 名歌手,大概 3 万 7 千多首,未经过任何清洗,当然有很多重复,比如说包含一些 live 的歌词。光陈奕迅一个人就有 1370 多首。
代码暂时放在这个 repo 里,到后面整合到完整的系统中:gaussic/crawl_scripts
如果需要现成的数据,我在百度云上面分享了一份:
链接:https://pan.baidu.com/s/1o9NNDjG 密码:0xe1
提示:
运行的代码的时候,发现半路上断了,估计是速度太快被禁止访问了,一个解决方案是,把抓完的歌手从 artists.txt 放到另外一个文件中,等一段时间,重新运行把剩下的抓了。另一个方案是,加代理,这样比较有效,不过速度比直接访问稍慢。经过测试,两者时间查不了太多。
下一篇再叙述,如何做一些数据清洗与简单的分析。
转载请注明出处:从零开始做歌词生成器 - 0 - 抓取网易云3万首歌词